Ce que cela signifie sur le plan opérationnel
L’humain dans la boucle est un modèle de contrôle, pas une vague réassurance. Il définit où les gens restent impliqués dans un flux de travail d'IA : avant l'envoi d'une réponse, avant l'exécution d'une action, lorsque la confiance est faible, lorsqu'un client est contrarié, lorsqu'un risque politique apparaît ou lorsque l'agent atteint une tâche qu'il n'est pas autorisé à accomplir.
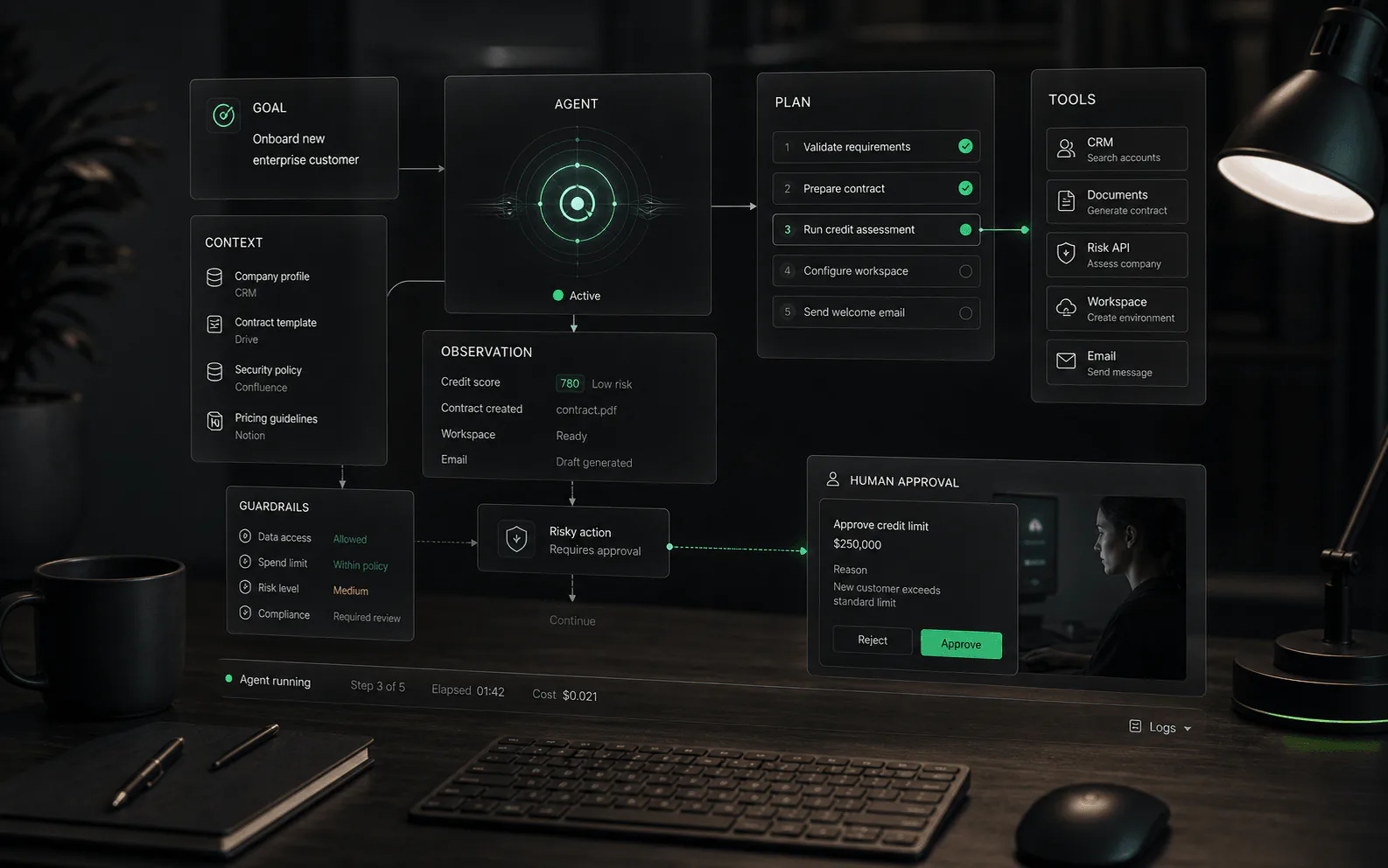
Comment fonctionne réellement l'humain dans la boucle
- Déclencheur : le flux de travail atteint une condition qui nécessite un jugement humain, comme une faible confiance, une valeur élevée, un contenu sensible, une action restreinte, un langage client en colère ou un contexte manquant.
- Package : le système envoie au réviseur suffisamment de contexte pour décider : historique des conversations, sources récupérées, enregistrement client, réponse proposée, action proposée et motif de l'escalade.
- Décision : l'humain approuve, modifie, rejette, réaffecte, demande plus d'informations ou reprend la conversation.
- Enregistrer : le système enregistre la proposition de l'agent, le changement humain, la décision finale, l'horodatage et le propriétaire.
- Améliorer : les équipes examinent les modèles de remplacements et d'escalades manquées pour mettre à jour les sources, les invites, les règles de flux de travail, les autorisations ou la formation des réviseurs.
Modèles de contrôle courants
- Révision avant envoi : l'agent rédige une réponse, mais une personne l'approuve ou la modifie avant que le client ne la voie.
- Approbation avant action : l'agent prépare une étape de mise à jour de compte, de remboursement, d'annulation ou de workflow, mais une personne doit approuver l'exécution.
- Routage des exceptions : l'agent gère les cas de routine mais fait remonter les interactions de faible confiance, sensibles, colériques ou de grande valeur.
- Prise de contrôle du superviseur : une personne peut entrer dans la conversation ou le flux de travail avec le contexte préservé.
- Audit post-action : les équipes examinent les conversations et les actions terminées pour identifier les problèmes de qualité, mais cela est plus faible que le contrôle en temps réel des flux de travail à risque.
Humain dans la boucle contre humain dans la boucle
Être humain dans la boucle signifie généralement qu'une personne fait partie du processus de décision avant qu'un résultat important ne soit atteint. L'humain dans la boucle signifie généralement qu'une personne surveille le système et peut intervenir, mais le système peut continuer à fonctionner à moins que la personne ne l'arrête. Les acheteurs doivent demander de quel modèle parle le vendeur. Pour un remboursement, un changement de compte ou une réponse d’assistance sensible, une surveillance après coup peut ne pas suffire.
Là où ça compte le plus
Le contrôle humain est particulièrement important lorsque le coût d’une mauvaise réponse est élevé. Cela inclut les remboursements, les litiges de facturation, l'accès au compte, les questions médicales ou juridiques, les conditions contractuelles, les clients mécontents, les comptes VIP, le langage réglementé, les actions irréversibles et tout flux de travail dans lequel l'agent pourrait exposer des données privées ou apporter une modification ayant un impact sur le client.
Concrete examples and non-examples
- Exemple : un agent rédige une recommandation de remboursement, mais un responsable du support doit l'approuver avant que l'argent ne soit restitué ou que les enregistrements du compte ne soient modifiés.
- Exemple : un client demande des conseils juridiques, médicaux ou spécifiques au contrat, et l'agent achemine la conversation vers un coéquipier qualifié au lieu de produire une réponse confiante.
- Exemple : un évaluateur voit les sources récupérées, la réponse proposée, la conversation précédente et l'action suivante suggérée avant d'approuver un message destiné au client.
- Non-exemple : une transcription est stockée après la fin de la conversation, mais personne ne peut intervenir avant que la réponse ou l'action ne parvienne au client.
- Non-exemple : un bouton de transfert de chat en direct existe, mais l'humain ne reçoit aucun résumé, aucune trace source, aucune tentative d'étape ou aucune raison de l'escalade.
Ce que les acheteurs doivent vérifier
- Quels événements déclenchent un examen humain, et l'entreprise peut-elle configurer ces déclencheurs ?
- Les réviseurs peuvent-ils modifier, approuver, rejeter, réaffecter ou prendre le relais, ou peuvent-ils uniquement consulter une transcription ?
- Le transfert inclut-il le contexte du client, les références sources, les étapes tentées et la raison de la remontée ?
- Les approbations sont-elles enregistrées avec l'utilisateur, l'horodatage, le contenu modifié et l'action finale ?
- Différentes équipes peuvent-elles appliquer différentes règles d'évaluation par flux de travail, canal, niveau de risque ou segment de clientèle ?
- Qu’arrive-t-il à l’expérience client pendant que le flux de travail attend une personne ?
Tests de démonstration pour la qualité de la surveillance
- Demandez à l'agent d'effectuer une action sensible et confirmez que la porte d'approbation apparaît avant l'exécution de l'action.
- Créez un scénario de client en colère et inspectez le contexte que l'humain reçoit lors de l'escalade.
- Demandez à un réviseur de modifier la réponse d'un agent et vérifiez que la piste d'audit finale montre le changement.
- Retardez la réponse des évaluateurs et voyez ce que le client ressent en attendant.
- Examinez les analyses pour détecter les escalades manquées, les fausses escalades, la charge des réviseurs et les modèles de remplacement.
Des compromis à prévoir
L’intégration humaine réduit les risques mais ne supprime pas le travail opérationnel. Les files d'attente de révision nécessitent du personnel, une priorisation, des attentes en matière de niveau de service et une appropriation de la remontée. Si chaque conversation nécessite une approbation, l'automatisation peut devenir plus lente que le processus d'origine. Si presque rien ne nécessite une approbation, le système peut créer un risque sous l’apparence d’un contrôle.
La conception des files d’attente est importante
Une file d’attente de révision humaine ne doit pas être constituée d’une seule pile d’exceptions. Cela nécessite des niveaux de priorité, des règles de propriété, un routage par expertise, des attentes en matière de niveau de service et un moyen de distinguer l'urgence du client de l'assurance qualité interne. Un litige de facturation, un problème de sécurité, un compte VIP, une question de routine sur un produit et une évaluation de la qualité du contenu ne doivent pas rivaliser aveuglément pour attirer la même attention.
Drapeaux rouges
Soyez prudent lorsqu'un fournisseur utilise le terme humain dans la boucle pour désigner uniquement un transfert générique de chat en direct, une transcription après coup ou une notification dans la boîte de réception d'assistance sans contrôle d'approbation. L'expression doit correspondre au comportement spécifique du produit : règles de déclenchement, actions des réviseurs, autorisations, journaux d'audit et expérience client claire lors du transfert.
Métriques à surveiller
Les mesures utiles incluent le volume de la file d'attente de révision, le temps d'approbation moyen, le taux de dérogation humaine, le taux de remontées manquées, le taux de fausses remontées, le temps d'attente des clients pendant la révision, le pourcentage d'actions sensibles approuvées par rôle et le nombre d'incidents détectés lors du contrôle qualité après résolution. Ces mesures permettent de déterminer si la surveillance améliore la qualité ou ajoute simplement des frictions.
Conception d'escalade
Une bonne conception humaine dans la boucle définit qui reçoit la réclamation, quel contexte il voit, quelle décision il peut prendre et ce que le client vit en attendant. Il doit également définir des règles de priorité : une approbation de remboursement, un problème de sécurité, une réclamation relative à la facturation et une question courante sur un produit ne doivent pas rester dans la même file d'attente indifférenciée. Le but n’est pas d’ajouter une personne partout ; il s’agit de placer le jugement humain là où il change le résultat.
Propriété après le lancement
L'examen humain a besoin d'un propriétaire. Quelqu'un doit ajuster les règles de remontée d'informations, inspecter les remplacements, former les réviseurs, gérer la charge de la file d'attente et décider quand un agent peut passer de l'examen obligatoire à l'assurance qualité échantillonnée. Sans appropriation, les équipes dérivent souvent vers deux mauvais schémas : tout approuver parce que la file d'attente est surchargée, ou tout faire remonter parce que personne ne fait confiance à l'automatisation.
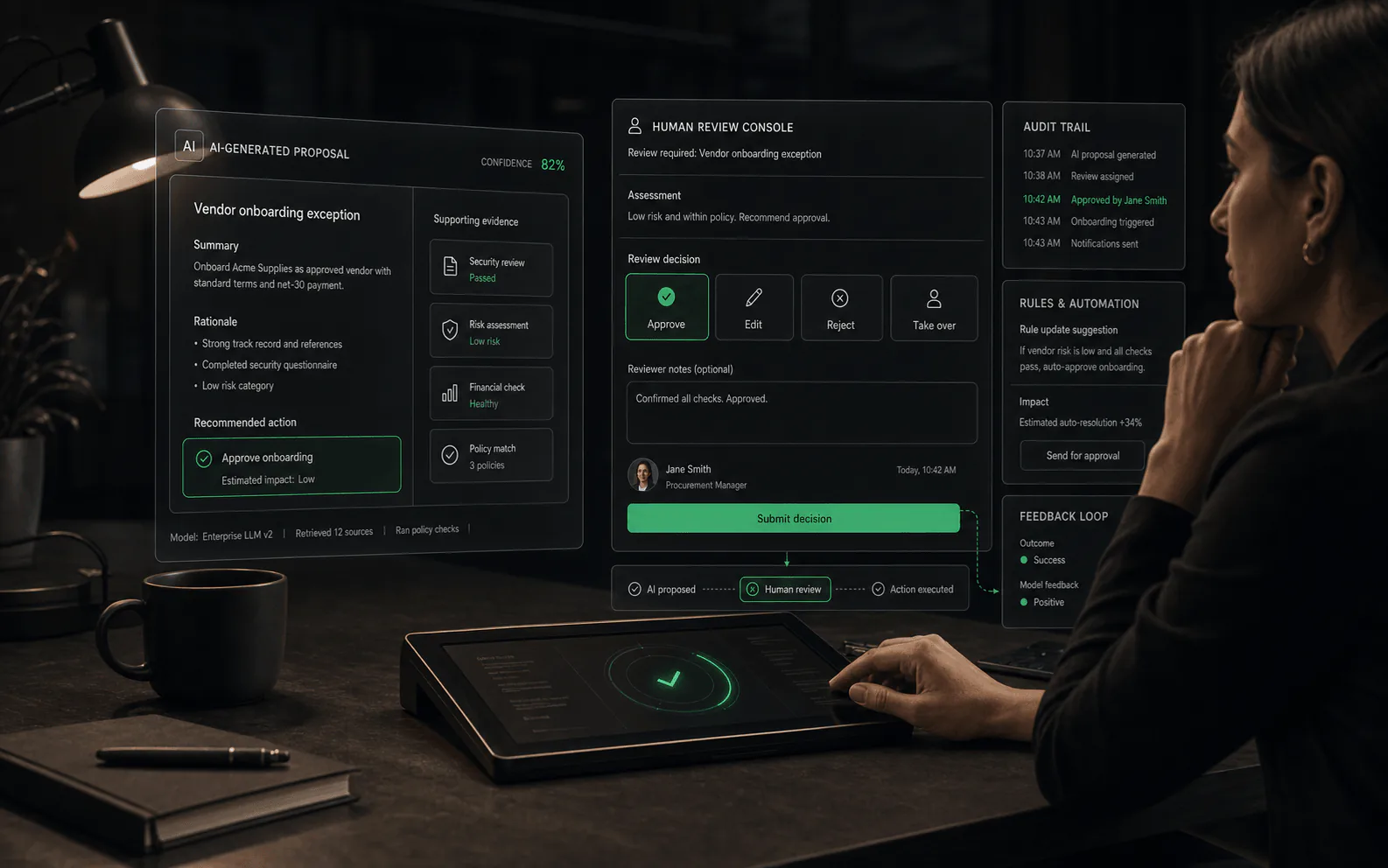
Examen assisté par l'IA
Toutes les décisions humaines ne doivent pas nécessairement partir de zéro. Certaines plates-formes utilisent l'IA pour aider les évaluateurs à travailler plus rapidement et de manière plus cohérente : en suggérant des modifications aux réponses de l'agent, en mettant en évidence les parties d'une source sur lesquelles l'agent s'est appuyé, en signalant les violations potentielles des politiques ou en affichant des indicateurs de confiance parallèlement à l'action proposée par l'agent.
Ceci est différent de l’agent qui rédige une réponse. L'examen assisté par l'IA signifie que l'humain voit les suggestions générées par la machine après l'agent a produit sa production, mais avant l'humain prend une décision finale. L’objectif est de réduire la charge cognitive et d’aider les évaluateurs à repérer les problèmes plus rapidement, et non de remplacer leur jugement.
- Exemple : un agent propose un remboursement. L'interface de révision affiche le montant du remboursement, la section de politique qui s'applique, un score de confiance et une option « approuver avec un message standard » en un clic. L'examinateur décide toujours, mais il n'a pas besoin de rechercher la politique ou de retaper une réponse commune.
- Exemple : un agent rédige une réponse client. L'interface de révision met en évidence quelles phrases proviennent de quels articles de la base de connaissances, afin que le réviseur puisse vérifier l'exactitude sans relire l'intégralité de la source.
- Exemple : le système signale qu'une réponse proposée contient des informations de tarification qui ont changé hier, invitant le réviseur à revérifier avant de l'envoyer.
- Non-exemple : l'agent propose une réponse et l'évaluateur ne voit qu'un pourcentage de confiance sans aucune explication sur ce qui a motivé ce score ou comment agir en conséquence.
Les acheteurs devraient se demander si l’assistance à l’examen réduit réellement le temps de décision sans introduire de nouveaux risques. Si les suggestions sont suffisamment fausses pour que les évaluateurs les ignorent, elles deviennent du bruit. Si les suggestions sont correctes mais que les évaluateurs les approuvent sans les lire, le système encourage l’approbation automatique.
Questions à poser dans les démos :
- Le critique peut-il voir pourquoi une suggestion a été faite, ou simplement la suggestion elle-même ?
- À quelle fréquence les évaluateurs acceptent-ils les suggestions de l’IA plutôt que de les ignorer ?
- Le réviseur peut-il modifier la suggestion avant de l'approuver, ou s'agit-il de tout ou rien ?
- Les suggestions s'adaptent-elles en fonction du comportement des évaluateurs passés, ou s'agit-il de règles statiques ?
- Que se passe-t-il lorsqu'une suggestion est erronée et que l'évaluateur la suit quand même ? Qui est responsable ?
Routage intelligent
Tous les cas remontés ne doivent pas être placés dans la même file d'attente. Le routage intelligent utilise les signaux de la conversation, du profil du client ou du comportement de l'agent pour décider lequel l'humain devrait examiner ou traiter un cas, et dans certains cas que ce soit cela nécessite l’attention humaine du tout.
Les décisions de routage combinent généralement plusieurs signaux : seuils de confiance du modèle, niveau ou segment de client, classification des sujets, sentiment, intention détectée, indicateurs réglementaires et capacité de file d'attente. L'objectif est de faire correspondre les cas avec des évaluateurs qui disposent de l'expertise, de la disponibilité et de l'autorité appropriées, tout en évitant les goulots d'étranglement où chaque exception atterrit dans une seule pile indifférenciée.
- Seuils de confiance : l'agent estime son degré de confiance dans l'action qu'il propose. En dessous d'un seuil configuré (disons 85 %), le cas est soumis à un examen. Au-dessus du seuil, cela peut se dérouler automatiquement, en fonction du flux de travail.
- Escalade basée sur la probabilité : au lieu d'une règle stricte, le système estime la probabilité que le cas nécessite une intervention humaine sur la base de cas similaires passés. Cela peut faire apparaître des cas limites qu’un seuil fixe ne permettrait pas de détecter.
- Transfert adaptatif : le système apprend des décisions des réviseurs au fil du temps. Si les réviseurs approuvent systématiquement certains types d’actions d’agent, le système peut réduire la probabilité de remontée de cas similaires à l’avenir. Si les évaluateurs annulent fréquemment, le système peut augmenter le seuil.
- Acheminement de l'expertise : les questions techniques sont acheminées vers des spécialistes techniques, les litiges de facturation vers des réviseurs formés à la facturation, les comptes VIP vers les cadres supérieurs et les sujets réglementés vers des réviseurs approuvés par la conformité.
Le routage intelligent échoue lorsque les signaux sont bruyants, lorsque les seuils sont définis sans données ou lorsque les examinateurs manipulent le système en approuvant tout pour vider leur file d'attente. Les acheteurs doivent tester le routage avec des cas extrêmes réalistes : un client qui semble en colère mais qui a une demande simple, une question technique provenant d'un compte VIP, une réponse peu fiable qui est en réalité correcte.
Questions à poser dans les démos :
- Quels signaux le modèle de routage utilise-t-il et pouvons-nous ajuster leurs poids ?
- Pouvons-nous définir différents seuils pour différents flux de travail, clients ou niveaux de risque ?
- Comment le routage change-t-il à mesure que les réviseurs approuvent ou remplacent les dossiers au fil du temps ?
- Pouvons-nous voir la décision d’acheminement expliquée, ou s’agit-il d’une boîte noire ?
- Que se passe-t-il lorsqu'aucun réviseur n'est disponible dans la file d'attente acheminée ?
Apprentissage continu grâce aux services correctionnels humains
L’humain dans la boucle n’est pas seulement un mécanisme de sécurité. Cela peut également être une source de données de formation. Lorsque les réviseurs modifient les réponses des agents, annulent des décisions ou fournissent des commentaires, le système peut tirer des leçons de ces corrections pour améliorer les performances futures.
L'apprentissage continu à partir des corrections signifie que la plate-forme capture ce que l'humain a changé, analyse les modèles dans de nombreuses corrections et utilise ces modèles pour mettre à jour les invites, les sources de récupération ou modéliser le comportement. Au fil du temps, l’agent devrait commettre moins d’erreurs du même type, réduisant ainsi le volume de cas nécessitant une attention humaine.
- Exemple : les évaluateurs modifient systématiquement les réponses de remboursement de l'agent pour ajouter une explication de la politique. Le système identifie ce modèle et met à jour l'invite pour inclure automatiquement le contexte de la stratégie. Les futures réponses de remboursement nécessiteront moins de modifications.
- Exemple : les évaluateurs marquent certains articles de la base de connaissances comme inutiles ou obsolètes. La plateforme réduit la dépendance à l'égard de ces sources ou les signale pour examen, améliorant ainsi la qualité de la récupération.
- Exemple : les évaluateurs rejettent un type d'action spécifique que l'agent propose en toute confiance. Le système apprend à diminuer la confiance ou à exiger l’approbation pour ce type d’action à l’avenir.
- Non-exemple : les évaluateurs modifient les réponses mais les modifications ne sont pas capturées, analysées ou réinjectées dans le système. Chaque correction est une solution ponctuelle et non une opportunité d'apprentissage.
Les acheteurs doivent comprendre comment les corrections sont réinjectées dans le système. Existe-t-il une boucle de rétroaction ou les corrections disparaissent-elles dans un journal ? Les équipes opérationnelles peuvent-elles voir des tendances globales dans les services correctionnels ? Peuvent-ils approuver ou rejeter les modifications proposées avant leur mise en ligne ? Combien de temps faut-il pour qu’un modèle de correction modifie le comportement de l’agent ?
L’apprentissage continu soulève également des questions de gouvernance. Si un évaluateur commet une erreur ou applique une politique non standard, le système doit-il tirer des leçons de cette correction ? Qui vérifie que le retour d’apprentissage est correct avant qu’il n’affecte d’autres cas ?
Questions à poser dans les démos :
- Comment les corrections humaines sont-elles capturées et stockées ?
- Pouvons-nous observer des tendances globales dans les corrections au fil du temps ?
- À quelle vitesse les corrections affectent-elles le comportement des agents ?
- Pouvons-nous approuver ou rejeter les modifications proposées avant leur mise en ligne ?
- Qu’est-ce qui empêche les commentaires incorrects des évaluateurs de dégrader le système ?
- Pouvons-nous annuler les modifications si une mise à jour d’apprentissage pose des problèmes ?
Qualité et fatigue des évaluateurs
Les évaluateurs humains ne sont pas interchangeables et ne sont pas des robots. Leur précision, leur rapidité et leur cohérence varient en fonction de la formation, de l'expérience, de la charge de travail, de l'heure de la journée et de l'état émotionnel. Un système humain dans la boucle qui ignore la qualité et la fatigue des évaluateurs finira par se dégrader, même si l’IA est bien conçue.
Les problèmes de qualité des évaluateurs se manifestent de plusieurs manières : décisions incohérentes entre les évaluateurs, dérive au fil du temps à mesure que les évaluateurs développent des raccourcis, précision moindre après de longues sessions et variation entre le personnel senior et subalterne. Certains évaluateurs approuvent tout pour vider leur file d'attente. D’autres escaladent prudemment pour éviter les risques. Certains lisent attentivement ; d'autres survolent.
La lassitude des évaluateurs est particulièrement importante à grande échelle. Un évaluateur qui traite 200 cas par jour prendra des décisions différentes dans ses 50 premiers cas par rapport aux 50 derniers. La pression du temps, les tâches répétitives et les cas difficiles contribuent tous à l'épuisement professionnel et à la baisse de la qualité.
- Exemple : une plateforme suit les taux d'accord des évaluateurs. Lorsque deux évaluateurs traitent des cas similaires, prennent-ils la même décision ? Un faible accord suggère des lignes directrices peu claires ou des jugements subjectifs qui nécessitent de meilleures normes.
- Exemple : un système détecte que le taux d'approbation d'un évaluateur est passé de 70 % à 95 % au cours de la dernière heure de son quart de travail. Cela peut indiquer une fatigue ou un virage, et la plate-forme peut le signaler pour un examen de qualité.
- Exemple : un système de routage limite un seul évaluateur à 50 cas à haut risque par jour, répartissant la charge pour maintenir la qualité. Après 50 cas, les éléments supplémentaires sont acheminés vers d'autres réviseurs disponibles.
- Non-exemple : tous les évaluateurs sont traités de la même manière, quelle que soit leur expérience, et leurs décisions ne sont jamais auditées pour en vérifier la cohérence ou la qualité.
Les acheteurs doivent se demander comment la plate-forme prend en charge la qualité des évaluateurs : sessions d'étalonnage, journaux de décision, échantillonnage d'assurance qualité, mesures d'accord et limites de charge de travail. Le système permet-il de voir facilement qui est en difficulté et qui a besoin de plus de formation ?
Questions à poser dans les démos :
- Pouvons-nous suivre l’accord et la cohérence des évaluateurs au fil du temps ?
- Y a-t-il des limites de charge de travail ou des indicateurs de fatigue intégrés au système ?
- Pouvons-nous vérifier les décisions des évaluateurs individuels et les comparer aux lignes directrices ?
- Comment le système gère-t-il les réviseurs qui approuvent tout ou font tout remonter ?
- Les évaluateurs seniors peuvent-ils encadrer ou remplacer les évaluateurs juniors au sein de l'outil ?
- Quelles mesures nous montrent lorsque la qualité des évaluateurs se dégrade ?
Conception SLA pour examen humain
Lorsqu'un agent IA passe la main à un humain, le client attend. Les accords de niveau de service pour l'examen humain définissent la durée de cette attente, la manière dont les retards sont communiqués et ce qui se passe lorsque les objectifs ne sont pas atteints. Une mauvaise conception des SLA transforme l’humain impliqué d’un élément de sécurité en un problème d’expérience client.
Les objectifs SLA dépendent du contexte. Un litige concernant la facturation peut justifier une réponse dans un délai de quatre heures, tandis qu'une question de routine sur un produit peut nécessiter une réponse dans un délai de vingt-quatre heures. Un compte VIP peut s’attendre à une attention quasi instantanée, tandis qu’un utilisateur de niveau gratuit comprend des attentes plus longues. Un client en colère dans un chat en direct a besoin d'une réponse en quelques minutes, tandis qu'une file d'attente de révision d'e-mails peut durer des heures.
Une conception SLA efficace répond à plusieurs questions :
- Quel est le temps de réponse cible pour chaque niveau de priorité ?
- Comment la priorité est-elle déterminée : par niveau de client, par type de problème, par risque détecté, par canal ?
- Que se passe-t-il lorsque l'objectif n'est pas atteint : le client reçoit-il une mise à jour, le cas s'aggrave-t-il, un responsable est-il averti ?
- Les objectifs SLA peuvent-ils être ajustés en fonction de l'heure de la journée, du jour de la semaine ou du niveau d'effectif ?
- Comment le temps d’attente est-il communiqué au client lors de l’examen ?
La priorisation des files d’attente est importante. Une file d'attente premier entré, premier sorti traite une demande de remboursement de la même manière qu'une question sur un produit, même si le remboursement comporte des enjeux plus élevés. Les files d'attente prioritaires acheminent les cas urgents plus rapidement, mais elles peuvent affamer les éléments de moindre priorité si elles ne sont pas gérées. Certaines plates-formes utilisent une file d'attente pondérée, des règles de vieillissement qui augmentent la priorité au fil du temps ou une escalade lorsque l'attente dépasse un seuil.
- Exemple : une plateforme propose trois niveaux de SLA : critique (réponse en 15 minutes), élevé (2 heures) et normal (24 heures). Les cas critiques incluent des problèmes de sécurité, des VIP en colère et des problèmes de réglementation. Les cas élevés incluent les litiges de facturation et les modifications de compte. Les cas normaux incluent des questions et des commentaires de routine.
- Exemple : lorsqu'un dossier reste en file d'attente pendant plus de la moitié de son objectif SLA, le système en informe un superviseur et offre la possibilité de le réaffecter ou de l'accélérer.
- Exemple : un client participant à un chat en direct voit une estimation du temps d'attente et un message de position dans la file d'attente pendant que son dossier attend l'approbation du réviseur. Si l'attente dépasse cinq minutes, le système propose de continuer par e-mail.
- Non-exemple : tous les dossiers entrent dans la même file d'attente sans priorisation, sans objectifs SLA, sans visibilité sur le temps d'attente et sans communication au client sur les retards.
La conception SLA est également liée à la dotation en personnel. Si une file d’attente manque systématiquement des cibles, la plate-forme doit présenter cela comme un problème de capacité, et non le cacher. Les tableaux de bord des réviseurs doivent afficher la profondeur de la file d'attente, le temps d'attente moyen et le risque de violation des SLA afin que les décisions en matière de personnel puissent être prises de manière proactive.
Questions à poser dans les démos :
- Pouvons-nous configurer différents objectifs SLA par priorité, segment de clientèle ou type de problème ?
- Comment les violations de SLA sont-elles détectées et communiquées ?
- Pouvons-nous voir les temps d'attente dans les files d'attente et les risques SLA dans les tableaux de bord des évaluateurs ?
- Quelle est l’expérience du client en attendant un avis ?
- Le système peut-il automatiquement remonter ou avertir les superviseurs lorsque les SLA sont menacés ?
- Comment la plateforme gère-t-elle les SLA sur tous les canaux : chat, e-mail, messagerie ?
Sources à vérifier
Utilisez ces références pour comprendre le terme et tester la pression des revendications des fournisseurs. Les détails spécifiques au produit doivent encore être vérifiés par rapport aux documents actuels du fournisseur.
FAQ
Questions courantes
L’humain dans la boucle est-il la même chose que le transfert humain ?
Pas exactement. Le transfert signifie généralement transférer une conversation à une personne. L'humain dans la boucle peut également inclure les portes d'approbation, les files d'attente de révision, la gestion des exceptions et le contrôle humain avant qu'une action automatisée ne soit terminée.
L’humain dans la boucle assure-t-il la sécurité d’un agent IA ?
Il aide à gérer les risques, mais il ne constitue pas un système de sécurité complet. Les acheteurs doivent toujours évaluer les autorisations, les tests, les journaux d’audit, le comportement de secours et la fréquence à laquelle un examen humain est réellement déclenché.
Quand l’examen humain devrait-il être obligatoire ?
L'examen obligatoire est particulièrement utile pour les actions irréversibles, les problèmes sensibles des clients, les modifications de compte, les remboursements, les litiges de facturation, les réponses peu fiables et les flux de travail pour lesquels le risque de politique ou de conformité est significatif.
Quelle est la différence entre un humain dans la boucle et un humain dans la boucle ?
Être humain dans la boucle signifie généralement qu'une personne fait partie du chemin de décision avant qu'une réponse ou une action ne soit terminée. L'humain dans la boucle signifie généralement qu'une personne surveille le système et peut intervenir, mais le système peut continuer à moins qu'il ne soit arrêté. Pour les flux de travail sensibles, les acheteurs doivent se demander si les humains peuvent modifier le résultat avant qu'il n'atteigne le client ou le système d'enregistrement.
Que doit voir un évaluateur humain avant d’approuver l’action d’un agent IA ?
Un réviseur doit voir l'historique des conversations, le contexte du client ou du compte, les sources récupérées, la réponse ou l'action proposée par l'agent, la raison pour laquelle le cas a été remonté et tous les indicateurs de risque pertinents. Si l’examinateur ne voit qu’une transcription sans trace de source ni action proposée, l’approbation peut devenir une conjecture plutôt qu’une surveillance significative.
L’humain dans la boucle peut-il ralentir le support ?
Oui. L'examen humain peut créer des files d'attente, des retards et des besoins en personnel si chaque cas à faible risque doit être approuvé. L'objectif est de placer l'examen là où le jugement change le résultat : actions sensibles, réponses peu fiables, clients VIP, clients mécontents, litiges de facturation ou changements irréversibles. Une bonne conception des files d’attente permet de maintenir le travail de routine tout en protégeant les cas à haut risque.
Comment mesurez-vous la qualité de l’humain dans la boucle ?
Les mesures utiles incluent le volume de la file d'attente de révision, le temps d'approbation moyen, le taux de dérogation, le taux de remontées manquées, le taux de fausses remontées, le temps d'attente des clients, l'accord des réviseurs, les incidents trouvés dans le contrôle qualité et la fréquence à laquelle les commentaires des révisions améliorent les invites, les sources ou les règles de flux de travail. Ces mesures montrent si la surveillance améliore les résultats ou ne fait qu’ajouter des frictions.
Quels sont les modes de défaillance courants liés à l'intervention humaine ?
Les échecs courants incluent les approbations automatiques, les files d'attente de révision surchargées, la propriété peu claire, les réviseurs sans suffisamment de contexte, les règles d'escalade trop larges ou trop étroites et la journalisation post-action présentée comme un contrôle en temps réel. Les acheteurs doivent tester le processus de révision avec des cas extrêmes réalistes avant de lui faire confiance en production.
À qui revient la responsabilité des flux de travail impliquant une intervention humaine ?
La propriété doit généralement être partagée. Les responsables des opérations ou du support doivent être propriétaires des règles de qualité et de révision des flux de travail, tandis que les équipes informatiques ou de sécurité possèdent les autorisations, la journalisation et l'accès au système. La clé est de nommer qui peut modifier les seuils de remontée d'informations, suspendre l'automatisation, former les réviseurs et décider quand un flux de travail passe de l'approbation obligatoire à un contrôle qualité échantillonné.
Qu’est-ce que l’examen assisté par l’IA et est-il utile ou nuisible à la surveillance ?
La révision assistée par l'IA signifie que la plateforme suggère des modifications, met en évidence la pertinence de la source ou affiche des indicateurs de confiance pour aider les réviseurs à travailler plus rapidement. Cela aide lorsque les suggestions réduisent la charge cognitive sans encourager l’approbation automatique. Si les évaluateurs approuvent les suggestions de l’IA sans les lire, ou si les suggestions sont fréquemment fausses et deviennent du bruit, la fonctionnalité peut dégrader la surveillance. Les acheteurs doivent vérifier si les suggestions expliquent leur raisonnement et suivre la fréquence à laquelle les évaluateurs les acceptent ou les ignorent.
Comment fonctionne le routage intelligent pour l’examen humain ?
Le routage intelligent utilise des signaux tels que les seuils de confiance, le niveau de client, la classification des sujets et les sentiments pour décider quel humain doit traiter un cas et s'il nécessite une attention humaine. L’objectif est de jumeler les cas avec des évaluateurs qui possèdent l’expertise, la disponibilité et l’autorité appropriées. Les acheteurs doivent se demander quels signaux déterminent les décisions de routage, si les seuils sont réglables et comment le routage s'adapte en fonction du comportement des évaluateurs au fil du temps.
Les corrections humaines améliorent-elles l’agent IA au fil du temps ?
Ils le peuvent, si la plateforme dispose d’une boucle de rétroaction. L'apprentissage continu à partir des corrections signifie que le système capture les modifications des réviseurs, analyse les modèles et met à jour les invites, les sources ou le comportement. Sans boucle de rétroaction, les corrections sont des correctifs ponctuels qui disparaissent dans un journal. Les acheteurs doivent se demander comment les corrections sont réinjectées dans le système, si les équipes peuvent voir des modèles globaux et si les modifications proposées nécessitent une approbation avant d'être mises en ligne.
Comment éviter que la fatigue des évaluateurs ne dégrade la qualité ?
La fatigue des évaluateurs se manifeste par des décisions incohérentes, une augmentation des taux d'approbation et une baisse de la qualité après de longues sessions. Les plates-formes peuvent aider en suivant les mesures d'accord des évaluateurs, en définissant des limites de charge de travail, en détectant les pics de taux d'approbation qui indiquent des raccourcis et en répartissant les cas à haut risque entre les évaluateurs. Les acheteurs doivent demander si la plate-forme affiche des mesures de qualité par évaluateur et si elle prend en charge l'étalonnage, l'échantillonnage d'assurance qualité et les limites de charge de travail.
Quels objectifs SLA devrions-nous fixer pour l’examen humain ?
Les objectifs SLA dépendent du contexte : canal, niveau client, type de problème et niveau de risque. Un litige de facturation peut justifier une réponse dans un délai de deux heures, tandis qu'une question de routine peut nécessiter un délai de vingt-quatre heures. Une conception SLA efficace inclut des niveaux de priorité, des règles de vieillissement des files d'attente, des notifications de violation et une communication avec les clients pendant l'attente. Les acheteurs doivent se demander si la plate-forme prend en charge les SLA configurables par segment, affiche le risque SLA dans les tableaux de bord des réviseurs et gère les violations avec élégance.