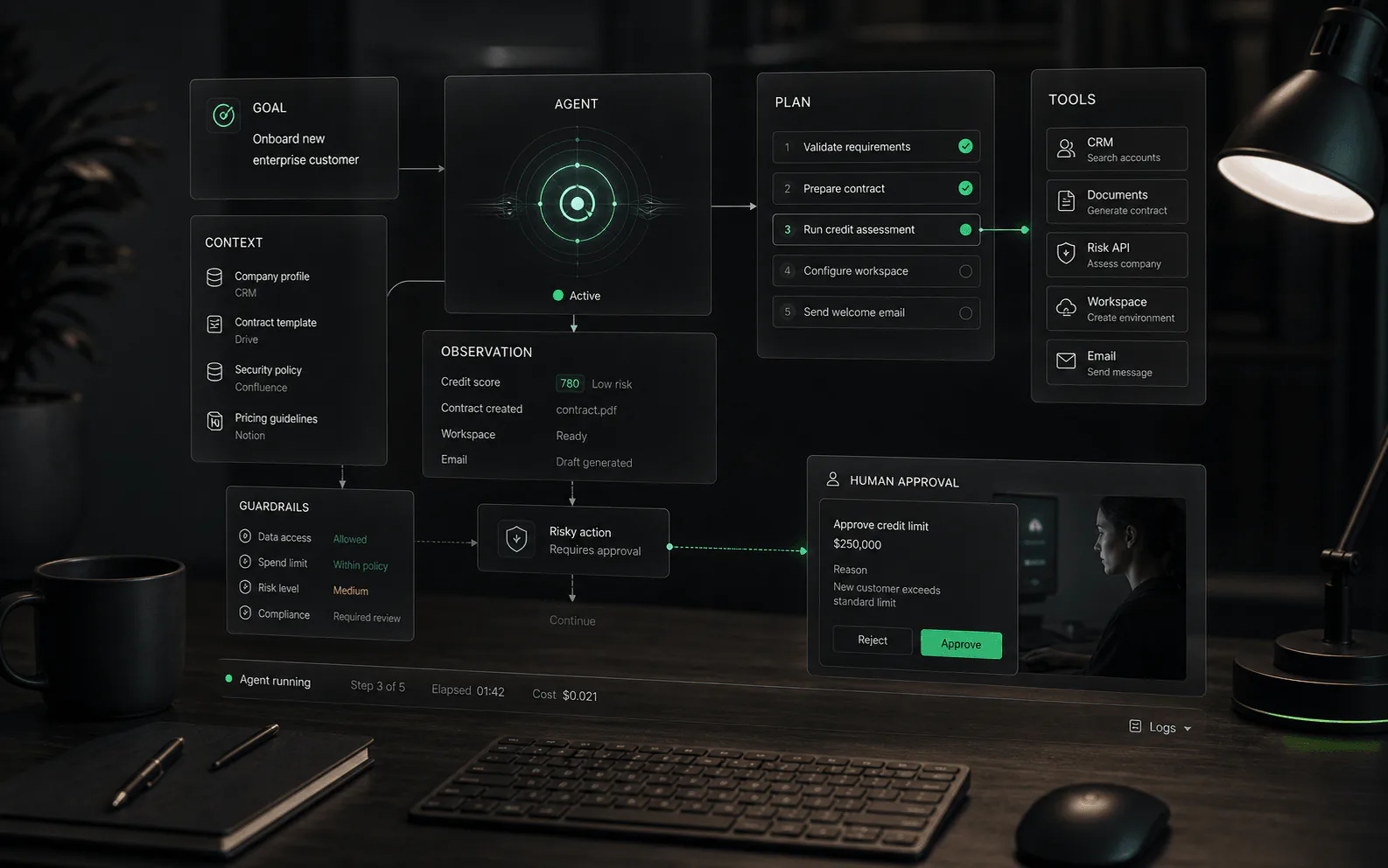
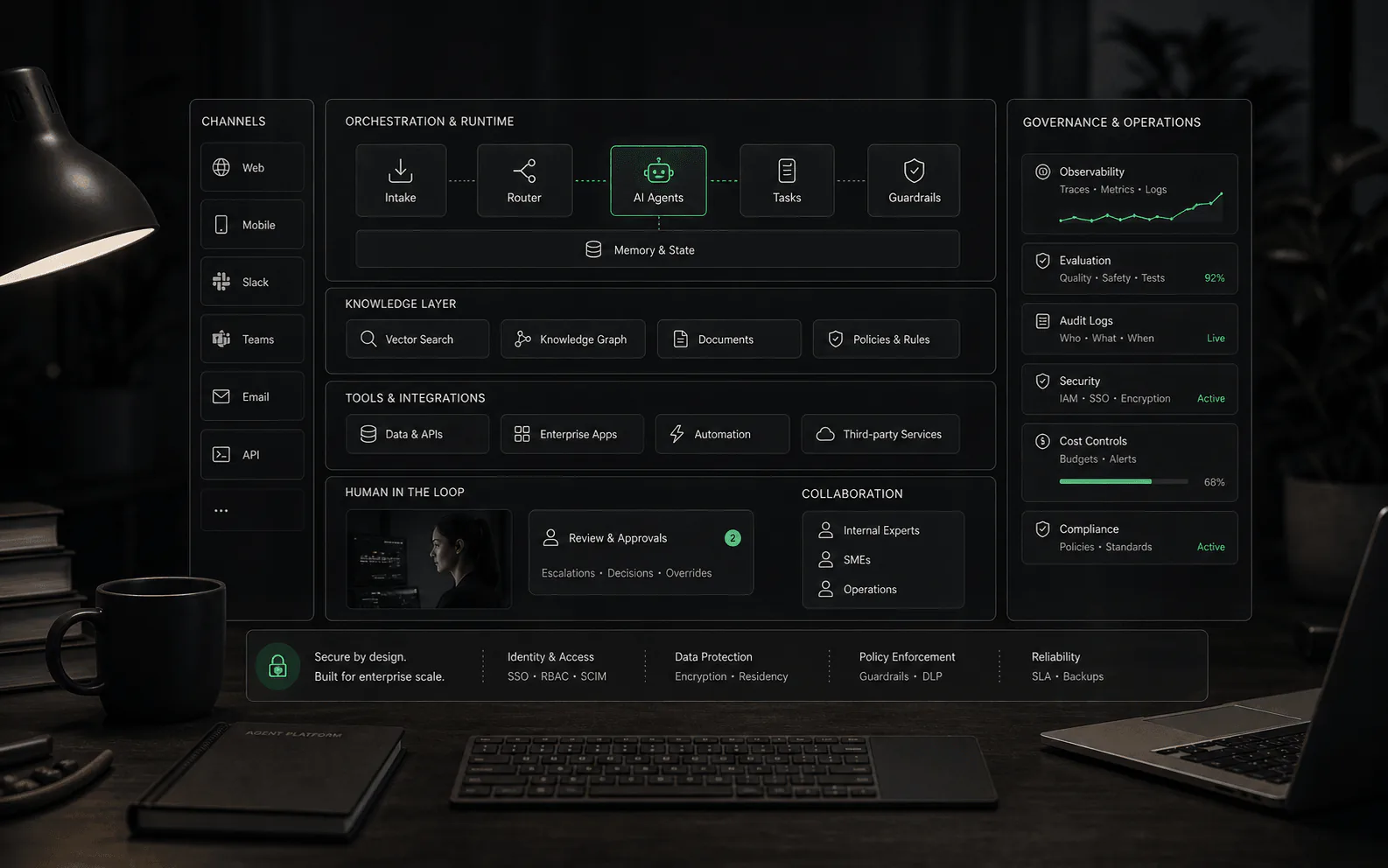
Ce que fait RAG
RAG connecte la génération à la récupération. Au lieu de demander à un modèle de répondre à partir de sa seule formation générale, le système recherche des sources approuvées, sélectionne des passages ou des enregistrements pertinents et utilise ce contexte pour produire une réponse. Dans les produits d'agent IA, ces sources peuvent inclure des centres d'aide, des documents internes, des manuels de produits, des pages de stratégie, des enregistrements CRM, des données de commande ou d'autres systèmes commerciaux, en fonction de ce que la plateforme prend en charge.
Comment fonctionne RAG
- Ingestion : les sources approuvées sont collectées à partir de documents, de centres d'aide, de bases de données, d'API ou d'autres référentiels.
- Préparer : le contenu est analysé, nettoyé, divisé en morceaux significatifs, étiqueté, autorisé et indexé pour la récupération.
- Récupérer : lorsqu'un utilisateur pose une question, le système recherche le matériel source pertinent à l'aide d'une recherche par mot clé, d'une recherche vectorielle, d'une recherche hybride, d'un reclassement ou d'une autre approche de récupération.
- Augmentation : le contexte sélectionné est assemblé dans l'invite du modèle avec des instructions sur la façon de l'utiliser.
- Générer : le modèle écrit une réponse en utilisant le contexte récupéré, idéalement avec une visibilité de la source pour les réviseurs ou les utilisateurs, le cas échéant.
- Améliorer : les requêtes ayant échoué et les réponses corrigées sont répercutées sur l'hygiène des sources, le réglage de la récupération et les ensembles d'évaluation.
Pourquoi c'est important pour les agents IA
RAG est l’un des principaux moyens par lesquels un agent IA devient spécifique à une entreprise. Un agent d'assistance qui ne peut pas récupérer la politique de remboursement actuelle, la règle de garantie, la page de tarification, les limitations du produit ou le contexte du compte produira souvent des réponses fluides mais peu fiables. Une bonne récupération ne rend pas le système parfait, mais elle donne à l'agent une meilleure chance de répondre à partir du matériel auquel l'entreprise fait réellement confiance.
RAG peut échouer à plusieurs niveaux
- Échec de la source : la bonne réponse est absente, périmée, dupliquée, contredite ou écrite d'une manière que le récupérateur ne peut pas utiliser.
- Échec de l'indexation : le contenu était mal fragmenté, mal étiqueté, intégré sans métadonnées utiles ou non actualisé après une mise à jour.
- Échec de récupération : le système trouve le mauvais passage, manque un synonyme, classe l'ancien contenu au-dessus du contenu actuel ou récupère du matériel que l'utilisateur ne devrait pas voir.
- Échec de mise à la terre : le modèle reçoit le bon contexte mais l'ignore, l'étend trop ou l'interprète mal.
- Expérience d'échec : la réponse semble confiante, mais ne donne aux évaluateurs aucune trace de source, aucun signal d'incertitude ou chemin d'escalade.
La qualité ne dépend pas seulement du téléchargement de fichiers
- Qualité des sources : des documents obsolètes, dupliqués, contradictoires ou mal structurés conduisent à de mauvaises réponses.
- Segmentation et indexation : le système doit diviser et stocker les connaissances de manière à en préserver le sens.
- Qualité de la récupération : l'agent doit trouver le bon contexte pour les questions complexes du monde réel, et pas seulement pour les correspondances exactes de mots clés.
- Gestion des autorisations : le contenu privé ou restreint à un rôle ne doit pas apparaître dans les réponses du mauvais utilisateur.
- Comportement de repli : le système doit savoir quand les sources sont manquantes, faibles ou conflictuelles au lieu d'inventer la certitude.
- Flux de travail de révision : les équipes ont besoin d'un moyen d'identifier les mauvaises réponses et de corriger le matériel source ou les règles de récupération.
Ce que les acheteurs devraient tester
- Posez des questions dont la réponse existe dans une source approuvée et nulle part ailleurs.
- Posez des questions lorsque deux documents sont en conflit et voyez si l'agent remarque une incertitude.
- Renseignez-vous sur une politique obsolète et vérifiez si la dernière source l'emporte.
- Posez des questions sensibles aux autorisations et confirmez que le contenu restreint reste restreint.
- Posez des questions sans source fiable et vérifiez si l'agent dit qu'il ne sait pas ou s'il escalade la situation.
- Vérifiez si les citations ou les extraits de sources sont accessibles aux humains pour le contrôle qualité.
Ensemble de données d'évaluation pour les démos RAG
Une démo RAG sérieuse doit utiliser un ensemble de tests restreint mais réaliste avant l'achat. Incluez des questions avec une source claire, des questions qui nécessitent deux sources, des questions avec des pièges obsolètes, des questions avec un contenu restreint, des questions qui ne devraient produire aucune réponse et des questions utilisant le langage du client plutôt que la terminologie interne. L’objectif est de séparer la fluidité des réponses de la qualité de la récupération.
Concrete examples and non-examples
- Exemple : un agent de support récupère la politique de garantie actuelle, cite la source pertinente en interne et répond uniquement dans les limites de cette politique.
- Exemple : un agent des opérations internes recherche dans une bibliothèque de procédures avant de rédiger l'étape suivante d'une demande d'un collaborateur.
- Exemple : un agent de commerce électronique récupère le contexte spécifique à la commande et la documentation du produit avant d'expliquer les informations dont un humain a besoin pour examiner un retour.
- Non-exemple : un modèle répond de mémoire générale sans vérifier les sources métiers agréées.
- Non-exemple : un fournisseur télécharge des documents une seule fois mais ne fournit aucun processus d'actualisation, aucun contrôle d'autorisation, aucune visibilité sur la source ou aucun rapport d'échec.
Formation RAG versus modèle
RAG n’est pas la même chose que former un modèle. La formation modifie le comportement du modèle grâce à un apprentissage supplémentaire. RAG récupère les informations externes au moment de la réponse. Pour les acheteurs, cette distinction est importante car RAG peut souvent refléter plus rapidement le contenu commercial mis à jour, mais elle dépend également fortement de la fraîcheur de la source, de l'indexation, des autorisations et de la qualité de la récupération.
RAG versus contexte long
Les modèles à contexte long peuvent accepter de grandes quantités de texte dans une invite, mais ce n'est pas automatiquement du RAG. RAG implique une récupération sélective : le système choisit le matériel pertinent à partir d'un ensemble de sources plus large avant la génération. Le transfert d'un fichier volumineux dans son contexte peut être utile pour des tâches spécifiques, mais cela ne résout pas à lui seul la fraîcheur des sources, les autorisations, le classement, la résolution des conflits ou les opérations de connaissances récurrentes.
Drapeaux rouges
Soyez sceptique lorsqu'un fournisseur considère le téléchargement d'un PDF comme une preuve de connaissances fiables. Surveillez également l'absence de visibilité sur la source, l'absence de contrôles d'actualisation, l'absence de modèle d'autorisation, l'absence de moyen de gérer les documents conflictuels, l'absence de reporting sur les questions sans réponse et l'absence de processus permettant d'améliorer une mauvaise récupération après le lancement.
Métriques à surveiller
La qualité du RAG doit être mesurée au-delà de la fluidité des réponses. Les signaux utiles incluent le taux de réussite de la récupération des questions à réponse connue, la fraîcheur des sources, le taux de requêtes non résolues, l'exactitude des citations, les échecs d'autorisation, les incidents de sources conflictuelles, le taux de correction des réponses et le nombre de questions échouées qui se transforment en améliorations des connaissances. Ces mesures aident à séparer le matériel source faible de la récupération faible et de la génération faible.
Opérations de connaissances
RAG crée un problème permanent d’opérations de connaissances. Quelqu'un doit décider quelles sources sont approuvées, supprimer les doublons, archiver les documents obsolètes, résoudre les conflits de politiques et examiner les questions auxquelles l'agent n'a pas pu répondre. Buyers should ask whether support operations, product operations, documentation, or IT will own that loop. Sans propriétaire nommé, la qualité de la récupération se dégrade généralement à mesure que les produits, les politiques et le langage du client changent.
Propriété après le lancement
Le propriétaire de la qualité RAG devrait avoir le pouvoir de modifier le matériel source, et pas seulement de lire les analyses. Si les équipes d'assistance constatent des échecs de récupération répétés mais que les propriétaires de documentation ne peuvent pas mettre à jour les articles rapidement, l'agent continuera à échouer de la même manière. Une boucle de fonctionnement utile relie les questions ayant échoué, les correctifs de source, la réindexation, les tests de régression et l'approbation du réviseur avant que les connaissances mises à jour ne soient approuvées en production.
RAG agentique
Agentic RAG étend le RAG traditionnel en permettant à l'agent IA d'effectuer plusieurs étapes de récupération, d'appeler des outils et d'affiner sa recherche en fonction de résultats intermédiaires. Au lieu d'une seule opération de récupération puis de génération, l'agent peut décider de rechercher à nouveau, d'essayer différentes requêtes, d'appeler des API ou de combiner des informations provenant de plusieurs sources via un raisonnement itératif. Cela est important pour les plateformes d'agents IA, car les questions commerciales complexes nécessitent souvent une enquête en plusieurs étapes : un agent d'assistance peut d'abord récupérer la politique de remboursement, puis vérifier l'état de la commande du client via l'API, puis récupérer les conditions de garantie spécifiques au produit avant de répondre.
- Récupération itérative : l'agent peut émettre plusieurs requêtes, affiner en fonction de ce qu'il trouve et décider quand arrêter la recherche.
- Augmentation des outils : l'agent combine la récupération de documents avec des recherches dans des bases de données, des appels d'API et des calculs, et pas seulement du texte statique.
- Autocorrection : lorsque la récupération initiale donne de mauvais résultats, l'agent peut reformuler, élargir ou pivoter plutôt que d'halluciner.
- Mémoire à travers les tours : le RAG agentique conserve souvent le contexte des tours précédents d'une conversation, permettant des questions de suivi sans tout récupérer.
- Planifier et exécuter : certains systèmes RAG agentiques planifient une stratégie de récupération avant de s'exécuter, réduisant ainsi les efforts inutiles sur des chemins non pertinents.
Pour les acheteurs évaluant les plateformes d’agents IA, les capacités agents RAG deviennent importantes lorsque le cas d’utilisation implique des enquêtes complexes en plusieurs étapes plutôt que de simples réponses de type FAQ. Demandez aux fournisseurs si la récupération s'effectue en un seul passage ou itérative, si l'agent peut appeler des outils en cours de récupération et comment le système gère les cas où la première recherche ne renvoie rien d'utile. Un système RAG à passage unique aura du mal à répondre à des questions telles que « pourquoi mon compte a-t-il été débité deux fois ce mois-ci ? » où la réponse nécessite de récupérer la politique de facturation, de vérifier l'historique des transactions via l'API et de comparer les dates.
Recherche hybride
La recherche hybride combine plusieurs méthodes de récupération (généralement par mot-clé (BM25), similarité vectorielle et parfois reclassement sémantique) pour améliorer la qualité de la récupération. La recherche par mot-clé pur manque de synonymes et de correspondances conceptuelles. La recherche vectorielle pure peut manquer des correspondances exactes ou être perturbée par l'intégration du bruit. La recherche hybride réduit les deux modes de défaillance en classant les résultats de plusieurs méthodes et en les fusionnant intelligemment.
- Recherche par mot-clé (BM25) : recherche des termes et expressions exacts. Fort pour les noms de produits, les SKU, les codes d’erreur et les identifiants spécifiques. Faible pour les questions conceptuelles ou les intentions paraphrasées.
- Recherche de vecteurs (sémantique) : correspond au sens en comparant les vecteurs d'intégration. Fort pour les questions paraphrasées, les correspondances conceptuelles et la récupération multilingue. Faible pour les identifiants exacts et parfois confus par des concepts à consonance similaire.
- Reclassement : un modèle de deuxième étape note les résultats initiaux avec plus de soin, souvent à l'aide d'un encodeur croisé qui évalue conjointement la requête et le document. Le reclassement améliore la précision au détriment de la latence.
- Fusion : les résultats de la recherche par mot-clé et par vecteur sont combinés à l'aide d'une fusion de classement réciproque ou d'une notation apprise, puis éventuellement reclassés.
Pour les acheteurs d’agents IA, la recherche hybride mérite souvent d’être posée. Un fournisseur qui s'appuie uniquement sur la recherche vectorielle peut manquer les correspondances exactes qu'un client s'attendrait à trouver. Un fournisseur qui s'appuie uniquement sur la recherche par mot-clé peut échouer avec des requêtes en langage naturel utilisant une formulation différente de celle de la documentation. Posez des questions de démonstration qui mélangent des besoins conceptuels et des besoins précis : « Quelle est la différence entre les niveaux tarifaires Pro et Entreprise ? » (nécessite de rechercher des pages de tarification et de comparer) ou « Comment corriger l'erreur 503 ? » (nécessite de faire correspondre le code d'erreur tout en comprenant le contexte).
Récupération multimodale
La récupération multimodale étend RAG au-delà du texte pour inclure des images, des tableaux, des vidéos, de l'audio et des données structurées. Les connaissances métier sont souvent multimodales : les manuels de produits contiennent des diagrammes et des tableaux, les centres d'aide incluent des captures d'écran, les tickets d'assistance sont accompagnés de photos et les documents de politique intègrent des graphiques. Un système RAG contenant uniquement du texte manquera des informations verrouillées dans des formats non textuels, ce qui entraînera des réponses incomplètes ou incorrectes.
- Images : récupération de diagrammes, de captures d'écran, de photos de produits et de captures d'écran d'erreur. Nécessite des intégrations compatibles avec la vision ou des pipelines OCR.
- Tableaux : extraction de données structurées à partir de PDF, de feuilles de calcul et de tableaux HTML. Les tableaux contiennent souvent des données de prix, de spécifications et de comparaison que la fragmentation du texte détruit.
- Vidéo et audio : indexation des horodatages, des transcriptions et des images visuelles des vidéos de formation, des webinaires et des appels d'assistance enregistrés.
- Données structurées : interrogation de bases de données, d'API et de graphiques de connaissances ainsi que de documents non structurés. Permet des réponses qui combinent une explication narrative avec des données en direct.
Pour les acheteurs, le support multimodal est important lorsque la base de connaissances inclut des actifs non textuels. Demandez si la plate-forme peut indexer et récupérer des PDF contenant des images intégrées, si les tableaux sont conservés en tant que données structurées plutôt que divisés en morceaux de texte incohérents, et si les requêtes basées sur des images (comme « montrez-moi le schéma de câblage du modèle X ») sont prises en charge. Une plate-forme qui indexe uniquement le texte renverra des réponses incomplètes pour les produits avec une documentation visuelle, des instructions d'assemblage avec des diagrammes ou des tickets d'assistance avec des captures d'écran d'erreur.
Stratégies de regroupement
Le découpage est la manière dont les documents sont divisés en unités récupérables avant l'indexation. La taille et le chevauchement des fragments affectent considérablement la qualité de la récupération. Les petits morceaux préservent des détails spécifiques mais perdent leur contexte. Les gros morceaux préservent le contexte mais diluent la pertinence et consomment le budget de la fenêtre contextuelle. Le chevauchement permet de garantir que les passages pertinents ne sont pas coupés aux limites. Le regroupement sémantique tente de se diviser aux limites des concepts plutôt qu'aux limites arbitraires des caractères ou des phrases.
- Taille du fragment : généralement 200 à 1 000 tokens. Des morceaux plus petits améliorent la précision pour des questions spécifiques mais peuvent manquer le contexte environnant. Les morceaux plus gros fournissent du contexte mais peuvent récupérer du matériel non pertinent.
- Chevauchement : un chevauchement de 10 à 20 % entre les fragments permet de garantir que les passages pertinents couvrent les limites des fragments. Aucun chevauchement ne risque de réduire de moitié les informations clés.
- Segmentation sémantique : utilise des intégrations ou une structure de phrases (titres, paragraphes, sections) pour diviser selon des limites de sens plutôt que des tailles fixes. Préserve les idées cohérentes mais nécessite plus de traitement.
- Segmentation parent-enfant : récupère de petits morceaux pour des raisons de pertinence, mais charge des morceaux parents plus gros pour le contexte. Équilibre précision et contexte.
- Segmentation de tables et de codes : nécessite une gestion particulière. Les tableaux doivent souvent être regroupés en unités ou en lignes avec des en-têtes conservés. Les morceaux de code nécessitent un contexte de fonction.
La qualité du fragmentation explique souvent pourquoi les mêmes documents produisent des réponses différentes selon les plateformes. Pour les acheteurs, demandez comment la plateforme gère le chunking, s'il existe des contrôles pour la taille et le chevauchement des chunks, si les tables et le code sont gérés spécialement et si le chunking peut être ajusté par type de document. Un fournisseur qui traite tous les documents de la même manière aura du mal à gérer des types de contenu mixtes : un manuel de politique PDF de 50 pages nécessite une segmentation différente de celle d'un ensemble de courtes entrées de FAQ.
Considérations sur le modèle d'intégration
Les modèles d'intégration convertissent le texte en représentations vectorielles pour la recherche sémantique. Le choix du modèle d'intégration affecte la qualité de la récupération, la couverture linguistique, la spécificité du domaine et le coût. Les modèles les plus récents surpassent souvent les anciens, mais le changement de modèle d'intégration nécessite de réindexer l'ensemble du corpus. Les acheteurs doivent comprendre quel modèle d'intégration utilise une plate-forme, à quelle fréquence elle est mise à jour et ce qui se passe lorsque les modèles sont mis à niveau.
- Qualité du modèle : les modèles d'intégration diffèrent par leur capacité à capturer la similarité sémantique, à gérer différentes langues et à représenter la terminologie spécifique au domaine. Un modèle formé sur du texte Web général peut avoir des difficultés avec la documentation médicale, juridique ou technique.
- Taille et vitesse du modèle : les modèles plus grands produisent souvent de meilleures intégrations mais coûtent plus cher à exploiter. Pour la récupération de gros volumes, le compromis entre qualité et latence est important.
- Adaptation du domaine : certaines plateformes permettent d'affiner les intégrations sur les données du domaine. Cela peut améliorer la récupération du vocabulaire spécialisé, mais ajoute de la complexité et des coûts de maintenance.
- Prise en charge multilingue : les modèles d'intégration varient en termes de couverture linguistique. Un modèle formé principalement en anglais peut avoir des performances médiocres dans d'autres langues, ce qui affectera les déploiements mondiaux.
- Mises à niveau et réindexation des modèles : lorsque les modèles d'intégration sont mis à jour ou remplacés, tous les documents doivent être réintégrés. Demandez si les mises à niveau sont automatiques, si elles entraînent des temps d'arrêt et si les régressions de la qualité de récupération sont surveillées.
Pour les acheteurs évaluant les plateformes, le choix du modèle d’intégration est souvent invisible mais impactant. Demandez quel modèle d'intégration est utilisé, s'il prend en charge les langues nécessaires, si une adaptation de domaine est disponible et ce qui se passe lorsque le modèle est mis à jour. Une plate-forme qui vous enferme dans un modèle d'intégration obsolète verra la qualité de la récupération se dégrader par rapport à celle des concurrents qui effectuent une mise à niveau.
Modèles de reclassement
Le reclassement est une étape de récupération de deuxième étape qui réévalue les résultats initiaux à l'aide d'un modèle plus puissant (généralement à codeur croisé). Après que la récupération initiale via une recherche par mot clé ou par vecteur ait renvoyé peut-être 50 à 100 passages candidats, un reclasseur évalue conjointement chaque paire requête-document pour produire un score de pertinence plus précis. Le reclassement améliore la précision au prix d’une latence supplémentaire.
- Encodeurs croisés : le modèle de reclassement voit à la fois la requête et le document ensemble, ce qui lui permet de capturer les interactions qui manquent aux modèles d'intégration de bi-encodeurs. Cela produit de meilleurs scores de pertinence mais est plus lent.
- API de reranking : certaines plateformes utilisent des API de reranking externes (Cohere, Jina, Voyage, etc.) tandis que d'autres hébergent des modèles de reranking en interne. Le reclassement hébergé en externe peut ajouter des problèmes de latence et de transfert de données.
- Sélection Top-k : le reclassement est généralement appliqué aux 20 à 100 meilleurs résultats initiaux. Après le reclassement, seuls les premiers sont transmis au modèle de génération.
- Compromis qualité-latence : le reclassement améliore la pertinence des réponses mais ajoute une latence de 50 à 500 ms par requête. Pour une assistance en temps réel, ce compromis doit être évalué.
- Coût : le reclassement est plus coûteux en termes de calcul que la récupération initiale. Pour les systèmes à volume élevé, le coût du reclassement de chaque requête s’additionne.
Pour les acheteurs, le reclassement est une capacité sur laquelle il faut poser des questions spécifiques. Une plateforme qui effectue uniquement une récupération initiale peut renvoyer des résultats moins pertinents pour les requêtes ambiguës. Une plateforme avec reclassement peut produire de meilleures réponses mais avec une latence et un coût plus élevés. Demandez si le reclassement est inclus, s'il est appliqué par défaut, s'il existe des contrôles permettant de déterminer quand reclasser et comment le fournisseur mesure l'amélioration de la qualité. Une démo qui semble parfaite sur des questions soigneusement choisies peut ne pas montrer l'intérêt d'un reclassement sur des requêtes désordonnées du monde réel.
Sources à vérifier
Utilisez ces références pour comprendre le terme et tester la pression des revendications des fournisseurs. Les détails spécifiques au produit doivent encore être vérifiés par rapport aux documents actuels du fournisseur.
FAQ
Questions courantes
RAG équivaut-il à entraîner un modèle d’IA ?
Non. La formation modifie le comportement du modèle. RAG récupère les informations externes au temps de réponse, la qualité dépend donc fortement des sources connectées, de la logique de récupération et de la fraîcheur du contenu indexé.
RAG prévient-il les hallucinations ?
Non. RAG peut réduire les réponses non prises en charge lorsque la qualité de la récupération et de la source est bonne, mais il ne garantit pas l'exactitude. Les acheteurs ont toujours besoin d’un comportement de secours, d’un examen des sources, de tests et d’une surveillance humaine pour les flux de travail à risque.
RAG est-il la même chose que la recherche sémantique ?
Non. La recherche sémantique permet de récupérer des informations pertinentes, souvent en faisant correspondre le sens plutôt que des mots-clés exacts. RAG utilise la récupération comme une étape dans un modèle plus vaste : récupérer le contexte pertinent, le transmettre à un modèle génératif et produire une réponse. Un système peut effectuer une recherche sémantique sans génération et générer du texte sans effectuer de récupération fiable.
Le téléchargement de documents vers un chatbot est-il la même chose que RAG ?
Pas tout seul. Les documents téléchargés peuvent être utilisés dans un système RAG si le chatbot récupère les passages pertinents de ces documents au moment de la réponse et les utilise comme contexte pour la génération. Mais un bouton de téléchargement de fichiers ne prouve pas comment fonctionne la récupération, si les bons passages sont sélectionnés, si les sources sont récentes ou si la réponse reste ancrée dans le matériel récupéré. Pour les acheteurs, le test consiste à inspecter l’étape de récupération, la visibilité de la source et le comportement en cas d’échec.
En quoi RAG est-il différent du réglage fin ?
Affiner les modifications du comportement du modèle en s'entraînant sur des exemples ou des données supplémentaires. RAG récupère les informations externes au moment de la réponse et les utilise comme contexte pour la réponse. RAG est souvent mieux adapté à l'évolution des connaissances métier, car les sources peuvent être mises à jour sans recyclage, mais la qualité dépend toujours de la récupération, des autorisations et de l'hygiène des sources.
Que doivent tester les acheteurs dans une démo RAG ?
Utilisez des questions avec une source claire, des questions nécessitant plusieurs sources, des pièges liés à des politiques obsolètes, du contenu sensible aux autorisations, des synonymes que les clients utilisent réellement et des questions pour lesquelles la bonne réponse devrait être inconnue. Demandez à voir les sources récupérées, pas seulement la réponse finale, afin de pouvoir savoir si la réponse était fondée ou simplement fluide.
Qu’est-ce qui pousse les systèmes RAG à donner de mauvaises réponses ?
Les mauvaises réponses peuvent provenir de sources obsolètes, de documents contradictoires, d'une mauvaise répartition, d'une récupération faible, de métadonnées manquantes, d'erreurs d'autorisation, de limites de fenêtre contextuelle ou d'un modèle qui ignore le matériel récupéré. Le débogage de RAG nécessite de séparer les problèmes de source, les problèmes de récupération, les problèmes de mise à la terre et les problèmes de génération au lieu de traiter chaque échec comme un problème immédiat.
À qui revient la qualité RAG après le lancement ?
La qualité RAG a besoin d’un propriétaire opérationnel ayant l’autorité nécessaire pour améliorer le matériel source. Les opérations de support, les opérations produit, la documentation ou la gestion des connaissances peuvent être responsables de la qualité du contenu, tandis que les équipes techniques sont responsables de l'indexation, des autorisations, de la configuration de la récupération et de la surveillance. Sans une boucle fermée entre les réponses échouées et les mises à jour des sources, la qualité de la récupération se dégrade généralement avec le temps.
RAG fonctionne-t-il avec des données privées ou autorisées ?
C’est possible, mais les acheteurs doivent vérifier soigneusement la gestion des autorisations. Le système doit respecter qui est autorisé à récupérer chaque source, si le contenu restreint peut apparaître dans les réponses, comment les modifications d'accès sont synchronisées et comment la récupération est enregistrée. Les erreurs d'autorisation peuvent transformer un système de connaissances utile en un risque d'exposition des données.
Quelle est la différence entre RAG et RAG agentique ?
Basic RAG récupère une fois et génère. Agentic RAG permet à l'agent d'effectuer plusieurs étapes de récupération, d'appeler des outils et d'affiner les recherches en fonction de résultats intermédiaires. Agentic RAG est plus adapté aux questions complexes en plusieurs étapes qui nécessitent de combiner des informations provenant de plusieurs sources ou API. Pour des questions simples de type FAQ, un RAG de base est souvent suffisant.
Pourquoi le chunking est-il important pour la qualité RAG ?
La segmentation détermine la manière dont les documents sont divisés en unités récupérables. Une mauvaise segmentation peut réduire de moitié les informations pertinentes, perdre le contexte autour des passages clés ou récupérer des fragments non pertinents. Des morceaux plus petits améliorent la précision mais perdent le contexte environnant. Des morceaux plus gros préservent le contexte mais diluent la pertinence. Le découpage sémantique tente de se diviser en fonction des limites de signification plutôt que des limites arbitraires, ce qui produit souvent de meilleurs résultats pour les documents complexes.
Dois-je interroger les fournisseurs sur la recherche hybride ?
Oui. La recherche hybride combine la récupération par mots clés et vectorielles, qui capture à la fois les correspondances exactes (comme les codes d'erreur et les noms de produits) et les correspondances conceptuelles (questions paraphrasées). Un système qui effectue uniquement une recherche vectorielle peut manquer des identifiants exacts. Un système qui effectue uniquement une recherche par mot-clé peut échouer sur les questions en langage naturel. Demandez si la plateforme prend en charge les deux, si le reclassement est inclus et comment les résultats sont fusionnés.
Ai-je besoin d’un RAG multimodal si mes documents sont principalement constitués de texte ?
Cela dépend de votre contenu. Si votre centre d'aide comprend des captures d'écran, des diagrammes de produits, des tableaux de prix ou des fichiers PDF avec des images intégrées, un système RAG contenant uniquement du texte manquera les informations verrouillées dans ces formats. Pour les produits comportant une documentation visuelle, des instructions d'assemblage ou des captures d'écran d'erreur, la récupération multimodale peut être essentielle. Demandez si la plateforme peut indexer et récupérer des images, des tableaux et des données structurées, pas seulement du texte.
Que dois-je savoir sur l’intégration de modèles ?
Les modèles d'intégration convertissent le texte en représentations vectorielles pour la recherche sémantique. Le choix du modèle affecte la qualité de la récupération, la couverture linguistique et la spécificité du domaine. Demandez quel modèle d'intégration utilise la plate-forme, si elle prend en charge les langues dont vous avez besoin, si l'adaptation de domaine est disponible et ce qui se passe lorsque le modèle est mis à jour. Le changement de modèle d'intégration nécessite la réindexation de tous les documents.
Le reclassement vaut-il la latence supplémentaire ?
Le reclassement améliore la pertinence en réévaluant les résultats initiaux avec un modèle plus puissant. Pour les requêtes ambiguës ou les grands ensembles de documents, le reclassement produit souvent de meilleures réponses. Le compromis est une latence supplémentaire (généralement 50 à 500 ms par requête) et un coût supplémentaire. Pour une assistance en temps réel lorsque la latence est importante, vérifiez si le reclassement améliore suffisamment la qualité des réponses pour justifier le retard. Pour les cas d’utilisation par lots ou asynchrones, le reclassement en vaut généralement la peine.