Was es operativ bedeutet
Der Mensch in der Schleife ist ein Kontrollmuster, keine vage Bestätigung. Es definiert, wo Personen in einen KI-Workflow eingebunden bleiben: bevor eine Antwort gesendet wird, bevor eine Aktion ausgeführt wird, wenn das Vertrauen gering ist, wenn ein Kunde verärgert ist, wenn ein Richtlinienrisiko auftritt oder wenn der Agent eine Aufgabe erreicht, die er nicht ausführen darf.
Wie Human-in-the-Loop tatsächlich funktioniert
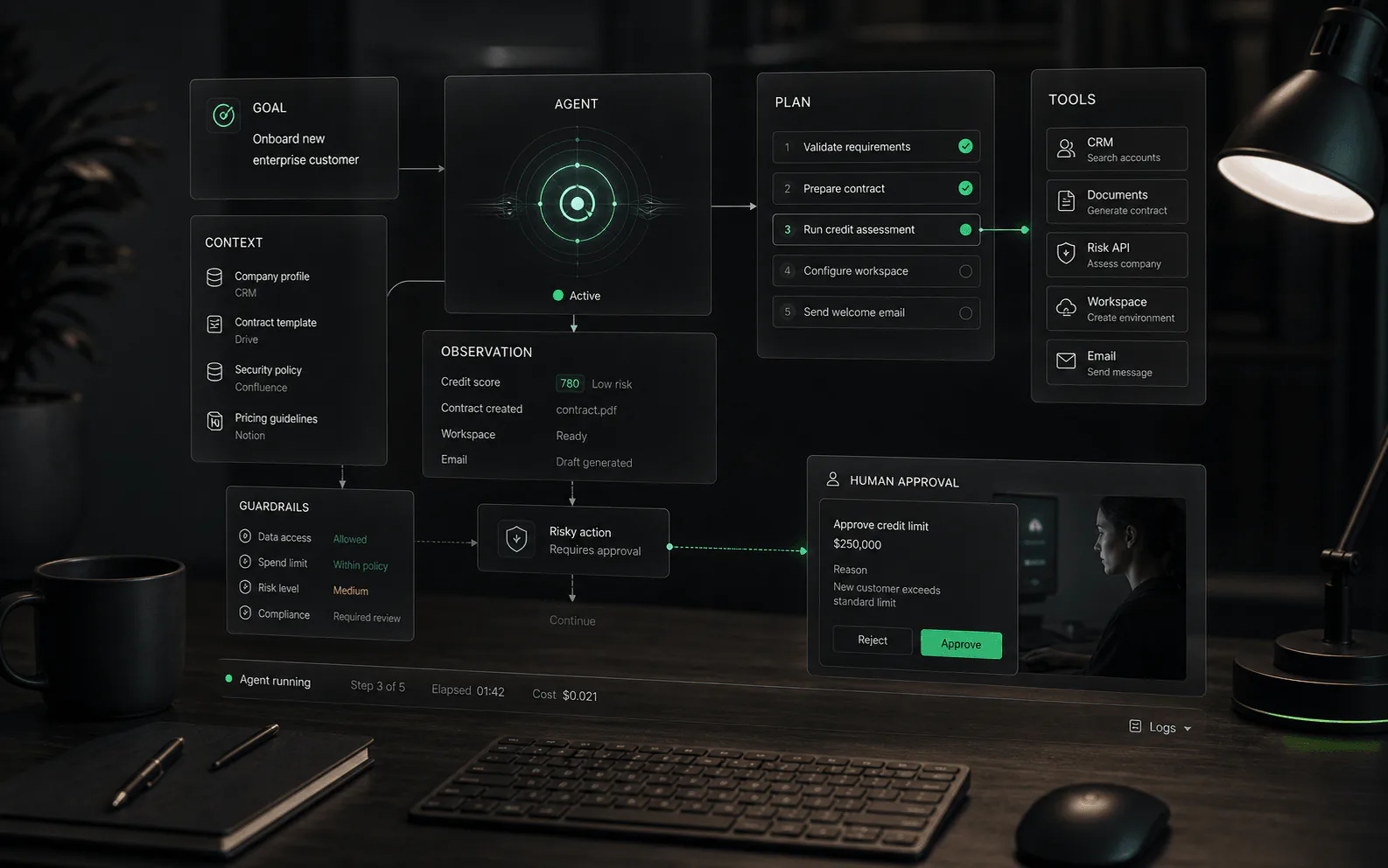
- Auslöser: Der Workflow erreicht einen Zustand, der menschliches Urteilsvermögen erfordert, z. B. geringes Vertrauen, hoher Wert, vertraulicher Inhalt, eingeschränkte Aktion, verärgerte Kundensprache oder fehlender Kontext.
- Paket: Das System sendet dem Prüfer genügend Kontext, um zu entscheiden: Gesprächsverlauf, abgerufene Quellen, Kundendatensatz, vorgeschlagene Antwort, vorgeschlagene Aktion und Grund für die Eskalation.
- Entscheidung: Der Mensch genehmigt, bearbeitet, lehnt ab, weist neue Aufgaben zu, fragt nach weiteren Informationen oder übernimmt das Gespräch.
- Aufzeichnung: Das System protokolliert den Agentenvorschlag, die menschliche Änderung, die endgültige Entscheidung, den Zeitstempel und den Eigentümer.
- Verbessern: Teams überprüfen Muster bei Überschreibungen und verpassten Eskalationen, um Quellen, Eingabeaufforderungen, Workflow-Regeln, Berechtigungen oder Prüferschulungen zu aktualisieren.
Gängige Steuerungsmodelle
- Überprüfung vor dem Senden: Der Agent erstellt eine Antwort, aber eine Person genehmigt oder bearbeitet sie, bevor der Kunde sie sieht.
- Genehmigung vor Aktion: Der Agent bereitet eine Kontoaktualisierung, Rückerstattung, Stornierung oder einen Workflow-Schritt vor, aber eine Person muss die Ausführung genehmigen.
- Ausnahmeweiterleitung: Der Agent bearbeitet Routinefälle, eskaliert jedoch wenig vertrauensvolle, sensible, verärgerte oder hochwertige Interaktionen.
- Übernahme durch den Vorgesetzten: Eine Person kann unter Beibehaltung des Kontexts in das Gespräch oder den Arbeitsablauf eintreten.
- Post-Action-Audit: Teams überprüfen abgeschlossene Gespräche und Aktionen, um Qualitätsprobleme zu identifizieren. Dies ist jedoch schwächer als die Echtzeitkontrolle für riskante Arbeitsabläufe.
Mensch in der Schleife versus Mensch in der Schleife
„Human in the Loop“ bedeutet in der Regel, dass eine Person am Entscheidungsprozess beteiligt ist, bevor ein wichtiges Ergebnis erreicht wird. „Mensch auf dem Laufenden“ bedeutet normalerweise, dass eine Person das System überwacht und eingreifen kann, das System jedoch möglicherweise weiter agiert, sofern die Person es nicht stoppt. Käufer sollten nachfragen, welches Modell ein Anbieter meint. Bei einer Rückerstattung, einer Kontoänderung oder einer sensiblen Support-Antwort reicht eine nachträgliche Überwachung möglicherweise nicht aus.
Wo es am wichtigsten ist
Die menschliche Kontrolle ist am wichtigsten, wenn die Kosten einer falschen Antwort hoch sind. Dazu gehören Rückerstattungen, Abrechnungsstreitigkeiten, Kontozugriff, medizinische oder rechtliche Fragen, Vertragsbedingungen, verärgerte Kunden, VIP-Konten, regulierte Sprache, unumkehrbare Handlungen und alle Arbeitsabläufe, bei denen der Agent private Daten preisgeben oder eine Änderung vornehmen könnte, die sich auf den Kunden auswirkt.
Konkrete Beispiele und Nicht-Beispiele
- Beispiel: Ein Agent entwirft eine Rückerstattungsempfehlung, aber ein Supportleiter muss diese genehmigen, bevor das Geld zurückgegeben oder die Kontodaten geändert werden.
- Beispiel: Ein Kunde bittet um rechtliche, medizinische oder vertragsspezifische Beratung und der Agent leitet das Gespräch an einen geschulten Teamkollegen weiter, anstatt eine sichere Antwort zu geben.
- Beispiel: Ein Prüfer sieht die abgerufenen Quellen, die vorgeschlagene Antwort, das vorherige Gespräch und die vorgeschlagene nächste Aktion, bevor er eine an den Kunden gerichtete Nachricht genehmigt.
- Kein Beispiel: Eine Mitschrift wird nach Ende des Gesprächs gespeichert, aber niemand kann eingreifen, bevor die Antwort oder Aktion den Kunden erreicht.
- Kein Beispiel: Es gibt eine Live-Chat-Übertragungsschaltfläche, aber der Mensch erhält keine Zusammenfassung, keinen Quellenpfad, keine versuchten Schritte oder keinen Grund für eine Eskalation.
Was Käufer überprüfen sollten
- Welche Ereignisse lösen eine menschliche Überprüfung aus und kann das Unternehmen diese Auslöser konfigurieren?
- Können Gutachter ein Transkript bearbeiten, genehmigen, ablehnen, neu zuweisen oder übernehmen oder können sie es nur ansehen?
- Enthält die Übergabe den Kundenkontext, Quellenverweise, versuchte Schritte und den Grund für die Eskalation?
- Werden Genehmigungen mit Benutzer, Zeitstempel, geändertem Inhalt und endgültiger Aktion erfasst?
- Können verschiedene Teams je nach Workflow, Kanal, Risikostufe oder Kundensegment unterschiedliche Überprüfungsregeln anwenden?
- Was passiert mit dem Kundenerlebnis, während der Workflow auf eine Person wartet?
Demotests zur Überwachungsqualität
- Bitten Sie den Agenten, eine sensible Aktion auszuführen und zu bestätigen, dass das Genehmigungstor angezeigt wird, bevor die Aktion ausgeführt wird.
- Erstellen Sie ein Szenario mit einem verärgerten Kunden und prüfen Sie, welchen Kontext der Mensch während der Eskalation erhält.
- Bitten Sie einen Prüfer, die Antwort eines Agenten zu bearbeiten und zu überprüfen, ob der endgültige Prüfpfad die Änderung zeigt.
- Verzögern Sie die Reaktion des Rezensenten und sehen Sie, was der Kunde während des Wartens erlebt.
- Überprüfen Sie Analysen auf verpasste Eskalationen, falsche Eskalationen, Prüferbelastung und Überschreibungsmuster.
Kompromisse, die man einplanen muss
Der Mensch im Kreislauf reduziert das Risiko, nimmt aber keine betriebliche Arbeit ab. Überprüfungswarteschlangen erfordern Personalausstattung, Priorisierung, Service-Level-Erwartungen und Eskalationsverantwortung. Wenn für jedes Gespräch eine Genehmigung erforderlich ist, kann die Automatisierung langsamer werden als der ursprüngliche Prozess. Wenn fast nichts einer Genehmigung bedarf, kann das System unter dem Anschein von Kontrolle Risiken schaffen.
Das Warteschlangendesign ist wichtig
Eine menschliche Überprüfungswarteschlange sollte kein einzelner Stapel von Ausnahmen sein. Es braucht Prioritätsstufen, Eigentumsregeln, Routing nach Fachwissen, Service-Level-Erwartungen und eine Möglichkeit, die Dringlichkeit des Kunden von der internen Qualitätssicherung zu unterscheiden. Ein Abrechnungsstreit, ein Sicherheitsbedenken, ein VIP-Konto, eine routinemäßige Produktfrage und eine Überprüfung der Inhaltsqualität sollten nicht blind um die gleiche Aufmerksamkeit des Rezensenten konkurrieren.
Rote Fahnen
Seien Sie vorsichtig, wenn ein Anbieter mit Human in the Loop nur eine generische Live-Chat-Übertragung, ein nachträgliches Transkript oder eine Support-Posteingangsbenachrichtigung ohne Genehmigungskontrollen meint. Der Satz sollte sich auf ein bestimmtes Produktverhalten beziehen: Auslöserregeln, Prüferaktionen, Berechtigungen, Prüfprotokolle und ein klares Kundenerlebnis während der Übergabe.
Zu überwachende Metriken
Zu den nützlichen Kennzahlen gehören das Volumen der Überprüfungswarteschlange, die durchschnittliche Genehmigungszeit, die Rate menschlicher Überschreibungen, die Rate verpasster Eskalationen, die Rate falscher Eskalationen, die Wartezeit des Kunden während der Überprüfung, der Prozentsatz der von der Rolle genehmigten sensiblen Aktionen und die Anzahl der bei der Qualitätssicherung nach der Lösung gefundenen Vorfälle. Anhand dieser Kennzahlen lässt sich erkennen, ob die Aufsicht die Qualität verbessert oder lediglich zu Reibungsverlusten führt.
Eskalationsdesign
Ein gutes Human-in-the-Loop-Design definiert, wer die Eskalation erhält, welchen Kontext er sieht, welche Entscheidung er treffen kann und was der Kunde während des Wartens erlebt. Außerdem sollten Prioritätsregeln festgelegt werden: Eine Rückerstattungsgenehmigung, ein Sicherheitsbedenken, eine Rechnungsbeschwerde und eine routinemäßige Produktfrage sollten nicht in derselben undifferenzierten Warteschlange stehen. The goal is not to add a person everywhere; Es geht darum, das menschliche Urteil dort zu platzieren, wo es das Ergebnis verändert.
Eigentum nach dem Start
Menschliche Überprüfung braucht einen Besitzer. Jemand muss Eskalationsregeln optimieren, Außerkraftsetzungen prüfen, Prüfer schulen, die Warteschlangenbelastung verwalten und entscheiden, wann ein Agent von der obligatorischen Prüfung zur stichprobenartigen Qualitätssicherung übergehen kann. Ohne Eigenverantwortung geraten Teams häufig in zwei schlechte Muster: Sie genehmigen alles, weil die Warteschlange überlastet ist, oder eskalieren alles, weil niemand der Automatisierung vertraut.
KI-gestützte Überprüfung
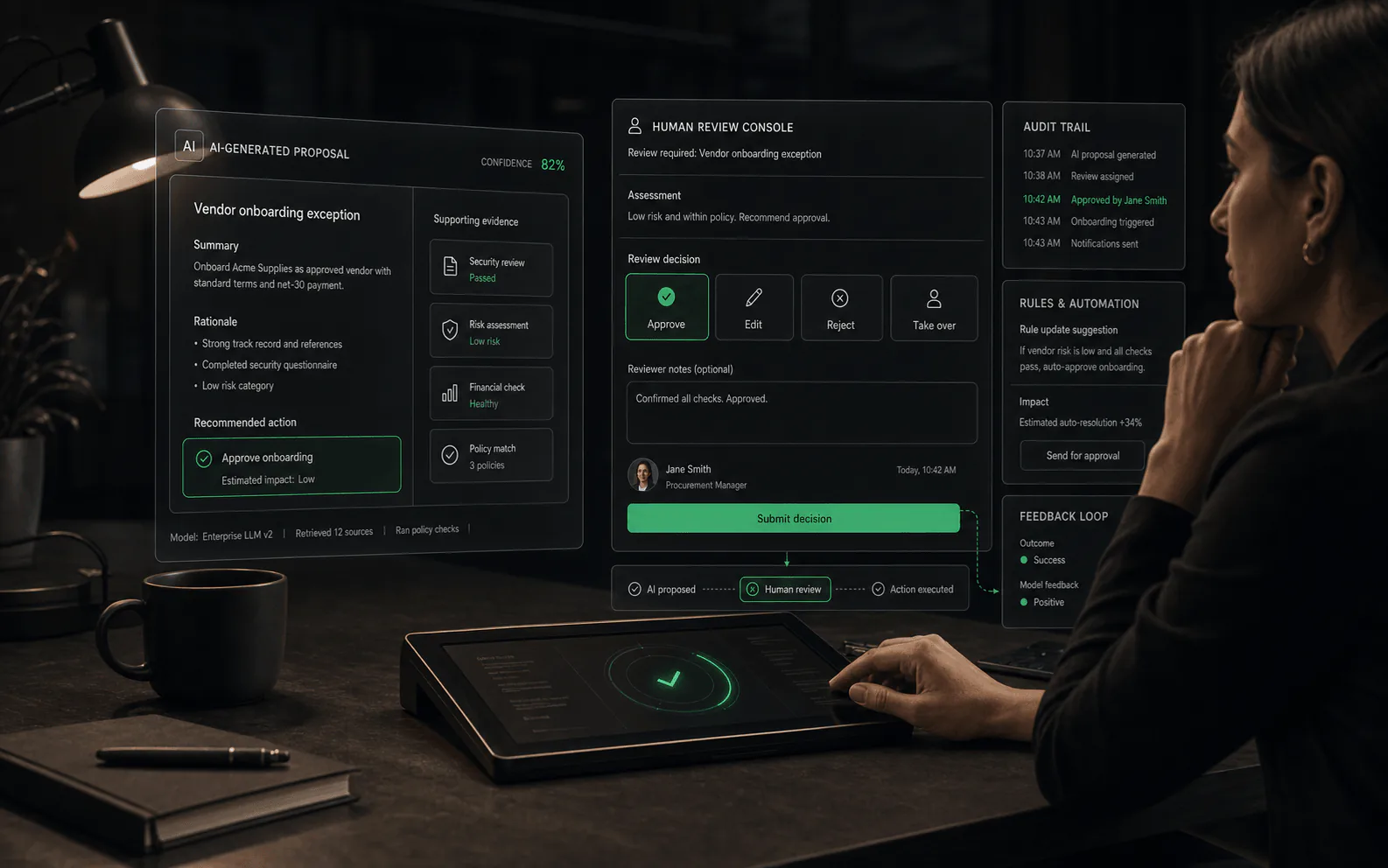
Nicht jede menschliche Entscheidung muss bei Null beginnen. Einige Plattformen nutzen KI, um Prüfern dabei zu helfen, schneller und konsistenter zu arbeiten: Sie schlagen Änderungen an Agentenantworten vor, heben hervor, auf welche Teile einer Quelle sich der Agent verlassen hat, kennzeichnen potenzielle Richtlinienverstöße oder zeigen neben der vom Agenten vorgeschlagenen Aktion Vertrauensindikatoren an.
Dies unterscheidet sich vom Verfassen einer Antwort durch den Agenten. KI-gestützte Überprüfung bedeutet, dass der Mensch maschinell generierte Vorschläge sieht danach Der Agent hat seine Ausgabe produziert, aber vor Der Mensch trifft eine endgültige Entscheidung. Das Ziel besteht darin, die kognitive Belastung zu reduzieren und Prüfern dabei zu helfen, Probleme schneller zu erkennen, und nicht darin, ihr Urteilsvermögen zu ersetzen.
- Beispiel: Ein Agent schlägt eine Rückerstattung vor. Die Überprüfungsoberfläche zeigt den Rückerstattungsbetrag, den geltenden Richtlinienabschnitt, einen Vertrauenswert und eine Ein-Klick-Option „Mit Standardnachricht genehmigen“ an. Der Prüfer entscheidet immer noch, muss aber nicht nach der Richtlinie suchen oder eine gemeinsame Antwort erneut eingeben.
- Beispiel: Ein Agent verfasst eine Kundenantwort. Die Überprüfungsoberfläche hebt hervor, welche Sätze aus welchen Wissensdatenbankartikeln stammen, sodass der Prüfer die Richtigkeit überprüfen kann, ohne die gesamte Quelle erneut lesen zu müssen.
- Beispiel: Das System markiert, dass eine vorgeschlagene Antwort Preisinformationen enthält, die sich gestern geändert haben, und fordert den Prüfer auf, die Antwort vor dem Senden noch einmal zu überprüfen.
- Kein Beispiel: Der Agent schlägt eine Antwort vor und der Prüfer sieht nur einen Konfidenzprozentsatz ohne Erklärung, was zu dieser Bewertung geführt hat oder wie er darauf reagieren soll.
Käufer sollten sich fragen, ob die Bewertungsunterstützung tatsächlich die Entscheidungszeit verkürzt, ohne neue Risiken mit sich zu bringen. Wenn Vorschläge so oft falsch sind, dass Rezensenten sie ignorieren, werden sie zu Lärm. Wenn Vorschläge richtig sind, die Gutachter sie aber genehmigen, ohne sie zu lesen, fördert das System die Zustimmung.
Fragen, die in Demos gestellt werden sollten:
- Kann der Rezensent sehen? warum wurde ein Vorschlag gemacht, oder nur der Vorschlag selbst?
- Wie oft akzeptieren Prüfer KI-Vorschläge, statt sie zu überschreiben?
- Kann der Prüfer den Vorschlag vor der Genehmigung bearbeiten, oder geht es um alles oder nichts?
- Passen sich die Vorschläge an das Verhalten früherer Prüfer an oder handelt es sich um statische Regeln?
- Was passiert, wenn ein Vorschlag falsch ist und der Prüfer ihm trotzdem folgt? Wer ist verantwortlich?
Intelligentes Routing
Nicht jeder eskalierte Fall sollte in dieselbe Warteschlange gelangen. Intelligentes Routing nutzt Signale aus dem Gespräch, dem Kundenprofil oder dem Agentenverhalten, um Entscheidungen zu treffen welche In einigen Fällen sollte ein Mensch einen Fall prüfen oder bearbeiten ob es braucht überhaupt menschliche Aufmerksamkeit.
Routing-Entscheidungen kombinieren typischerweise mehrere Signale: Vertrauensschwellenwerte aus dem Modell, Kundenebene oder -segment, Themenklassifizierung, Stimmung, erkannte Absicht, regulatorische Flags und Warteschlangenkapazität. Das Ziel besteht darin, Fälle mit Prüfern zusammenzubringen, die über das richtige Fachwissen, die richtige Verfügbarkeit und die richtige Autorität verfügen, und gleichzeitig Engpässe zu vermeiden, bei denen jede Ausnahme auf einem einzigen undifferenzierten Stapel landet.
- Konfidenzschwellen: Der Agent schätzt, wie sicher er von der vorgeschlagenen Aktion ist. Unterhalb eines konfigurierten Schwellenwerts (z. B. 85 Prozent) wird der Fall zur Überprüfung weitergeleitet. Oberhalb des Schwellenwerts kann es je nach Workflow automatisch weitergehen.
- Wahrscheinlichkeitsbasierte Eskalation: Anstelle einer harten Regel schätzt das System die Wahrscheinlichkeit, dass der Fall menschliches Eingreifen erfordert, basierend auf früheren ähnlichen Fällen. Dies kann Grenzfälle aufdecken, die ein fester Schwellenwert übersehen würde.
- Adaptive Übergabe: Das System lernt im Laufe der Zeit aus den Entscheidungen der Prüfer. Wenn Prüfer durchgängig bestimmte Arten von Agentenaktionen genehmigen, kann das System die Eskalationswahrscheinlichkeit für ähnliche zukünftige Fälle senken. Wenn Prüfer häufig Überschreibungen vornehmen, kann das System den Schwellenwert erhöhen.
- Weiterleitung von Fachwissen: Technische Fragen werden an technische Spezialisten weitergeleitet, Abrechnungsstreitigkeiten an in der Abrechnung geschulte Prüfer, VIP-Konten an leitende Mitarbeiter und regulierte Themen an Compliance-zugelassene Prüfer.
Intelligentes Routing bricht zusammen, wenn Signale verrauscht sind, wenn Schwellenwerte ohne Daten festgelegt werden oder wenn Prüfer das System austricksen, indem sie alles genehmigen, um ihre Warteschlange zu leeren. Käufer sollten das Routing mit realistischen Grenzfällen testen: ein Kunde, der verärgert klingt, aber eine einfache Anfrage hat, eine technische Frage von einem VIP-Konto, eine wenig vertrauenswürdige Antwort, die tatsächlich richtig ist.
Fragen, die in Demos gestellt werden sollten:
- Welche Signale verwendet das Routing-Modell und können wir deren Gewichtung anpassen?
- Können wir unterschiedliche Schwellenwerte für unterschiedliche Arbeitsabläufe, Kunden oder Risikostufen festlegen?
- Wie ändert sich die Weiterleitung, wenn Prüfer im Laufe der Zeit Fälle genehmigen oder außer Kraft setzen?
- Können wir uns die Routing-Entscheidung erklären lassen oder handelt es sich um eine Blackbox?
- Was passiert, wenn in der weitergeleiteten Warteschlange kein Prüfer verfügbar ist?
Kontinuierliches Lernen aus menschlichen Korrekturen
Human-in-the-Loop ist nicht nur ein Sicherheitsmechanismus. Es kann auch eine Quelle für Trainingsdaten sein. Wenn Prüfer Agentenantworten bearbeiten, Entscheidungen außer Kraft setzen oder Feedback geben, kann das System aus diesen Korrekturen lernen, um die zukünftige Leistung zu verbessern.
Kontinuierliches Lernen aus Korrekturen bedeutet, dass die Plattform erfasst, was der Mensch geändert hat, Muster über viele Korrekturen hinweg analysiert und diese Muster verwendet, um Eingabeaufforderungen, Abrufquellen oder Modellverhalten zu aktualisieren. Im Laufe der Zeit sollte der Agent weniger Fehler derselben Art machen, wodurch sich die Anzahl der Fälle verringert, die menschliche Aufmerksamkeit erfordern.
- Beispiel: Prüfer bearbeiten regelmäßig die Rückerstattungsantworten des Agenten, um eine Richtlinienerklärung hinzuzufügen. Das System erkennt dieses Muster und aktualisiert die Eingabeaufforderung automatisch, um den Richtlinienkontext einzuschließen. Zukünftige Rückerstattungsantworten erfordern weniger Bearbeitungen.
- Beispiel: Rezensenten markieren bestimmte Wissensdatenbankartikel als nicht hilfreich oder veraltet. Die Plattform verringert die Abhängigkeit von diesen Quellen oder markiert sie zur Überprüfung und verbessert so die Abrufqualität.
- Beispiel: Gutachter lehnen eine bestimmte Art von Aktion ab, die der Agent selbstbewusst vorschlägt. Das System lernt, das Vertrauen für diesen Aktionstyp in Zukunft zu verringern oder eine Genehmigung zu verlangen.
- Kein Beispiel: Prüfer bearbeiten Antworten, aber die Änderungen werden nicht erfasst, analysiert oder in das System zurückgemeldet. Jede Korrektur ist eine einmalige Lösung und keine Lernmöglichkeit.
Käufer sollten verstehen, wie Korrekturen in das System zurückfließen. Gibt es eine Feedbackschleife oder verschwinden Korrekturen in einem Protokoll? Können Betriebsteams aggregierte Muster in Korrekturen erkennen? Können sie vorgeschlagene Änderungen genehmigen oder ablehnen, bevor sie in Betrieb gehen? Wie lange dauert es, bis ein Korrekturmuster das Verhalten eines Agenten ändert?
Kontinuierliches Lernen wirft auch Governance-Fragen auf. Sollte das System aus dieser Korrektur lernen, wenn ein Prüfer einen Fehler macht oder eine nicht standardmäßige Richtlinie anwendet? Wer überprüft, ob das Lernfeedback korrekt ist, bevor es sich auf andere Fälle auswirkt?
Fragen, die in Demos gestellt werden sollten:
- Wie werden menschliche Korrekturen erfasst und gespeichert?
- Können wir im Laufe der Zeit aggregierte Muster bei Korrekturen erkennen?
- Wie schnell wirken sich Korrekturen auf das Agentenverhalten aus?
- Können wir vorgeschlagene Änderungen genehmigen oder ablehnen, bevor sie in Kraft treten?
- Was verhindert, dass falsches Gutachter-Feedback das System beeinträchtigt?
- Können wir Änderungen rückgängig machen, wenn ein Lernupdate Probleme verursacht?
Qualität und Ermüdung der Rezensenten
Menschliche Gutachter sind nicht austauschbar und keine Roboter. Ihre Genauigkeit, Geschwindigkeit und Konsistenz variieren je nach Training, Erfahrung, Arbeitsbelastung, Tageszeit und emotionalem Zustand. Ein „Human-in-the-Loop“-System, das die Qualität und Ermüdung der Prüfer ignoriert, wird sich irgendwann verschlechtern, selbst wenn die KI gut konzipiert ist.
Qualitätsprobleme der Prüfer zeigen sich auf verschiedene Weise: inkonsistente Entscheidungen zwischen Prüfern, Abweichungen im Laufe der Zeit, wenn Prüfer Abkürzungen entwickeln, geringere Genauigkeit nach langen Sitzungen und Unterschiede zwischen leitenden und jüngeren Mitarbeitern. Einige Rezensenten genehmigen alles, um ihre Warteschlange freizumachen. Andere eskalieren vorsichtig, um Risiken zu vermeiden. Einige lesen sorgfältig; andere überfliegen.
Die Ermüdung der Prüfer ist im großen Maßstab besonders wichtig. Ein Gutachter, der täglich 200 Fälle bearbeitet, trifft in den ersten 50 Fällen andere Entscheidungen als in den letzten 50. Zeitdruck, sich wiederholende Aufgaben und schwierige Fälle tragen alle zu Burnout und Qualitätsverlust bei.
- Beispiel: Eine Plattform verfolgt die Zustimmungsraten der Gutachter. Treffen zwei Gutachter die gleiche Entscheidung, wenn sie ähnliche Fälle bearbeiten? Eine geringe Übereinstimmung deutet auf unklare Richtlinien oder subjektive Urteile hin, die bessere Standards erfordern.
- Beispiel: Ein System erkennt, dass die Zustimmungsrate eines Prüfers in der letzten Stunde seiner Schicht von 70 Prozent auf 95 Prozent gestiegen ist. Dies kann auf Ermüdung oder Fehler hinweisen und die Plattform kann dies zur Qualitätsprüfung markieren.
- Beispiel: Ein Routing-System begrenzt jeden einzelnen Prüfer auf 50 Fälle mit hohem Risiko pro Tag und verteilt die Last so, dass die Qualität erhalten bleibt. Nach 50 Fällen werden zusätzliche Elemente an andere verfügbare Prüfer weitergeleitet.
- Kein Beispiel: Alle Gutachter werden unabhängig von ihrer Erfahrung gleich behandelt und ihre Entscheidungen werden niemals auf Konsistenz oder Qualität überprüft.
Käufer sollten sich fragen, wie die Plattform die Prüferqualität unterstützt: Kalibrierungssitzungen, Entscheidungsprotokolle, QA-Stichproben, Vereinbarungsmetriken und Arbeitsbelastungsgrenzen. Lässt sich anhand des Systems leicht erkennen, wer Probleme hat und wer mehr Schulung benötigt?
Fragen, die in Demos gestellt werden sollten:
- Können wir die Zustimmung und Konsistenz der Gutachter im Laufe der Zeit verfolgen?
- Sind im System Belastungsgrenzen oder Ermüdungsindikatoren integriert?
- Können wir die Entscheidungen einzelner Gutachter prüfen und sie mit Richtlinien vergleichen?
- Wie geht das System mit Prüfern um, die alles genehmigen oder alles eskalieren?
- Können leitende Gutachter innerhalb des Tools Nachwuchsgutachter betreuen oder über sie verfügen?
- Welche Kennzahlen zeigen uns, wenn die Qualität der Rezensenten nachlässt?
SLA-Design zur menschlichen Überprüfung
Wenn ein KI-Agent an einen Menschen übergibt, wartet der Kunde. Service-Level-Agreements für die menschliche Überprüfung legen fest, wie lange diese Wartezeit dauern sollte, wie Verzögerungen kommuniziert werden und was passiert, wenn Ziele nicht erreicht werden. Schlechtes SLA-Design macht Human-in-the-Loop von einem Sicherheitsmerkmal zu einem Problem für das Kundenerlebnis.
SLA-Ziele hängen vom Kontext ab. Bei einem Rechnungsstreit kann eine Antwort innerhalb von vier Stunden erforderlich sein, während bei einer routinemäßigen Produktfrage möglicherweise vierundzwanzig Stunden vergehen. Ein VIP-Konto kann nahezu sofortige Aufmerksamkeit erwarten, während ein Benutzer mit der kostenlosen Stufe längere Wartezeiten in Kauf nimmt. Ein verärgerter Kunde in einem Live-Chat benötigt eine Antwort innerhalb von Minuten, während eine E-Mail-Bewertungswarteschlange stundenlang dauern kann.
Ein effektives SLA-Design beantwortet mehrere Fragen:
- Wie hoch ist die angestrebte Reaktionszeit für jede Prioritätsstufe?
- Wie wird die Priorität bestimmt: nach Kundenstufe, nach Problemtyp, nach erkanntem Risiko, nach Kanal?
- Was passiert, wenn das Ziel verfehlt wird: Erhält der Kunde ein Update, eskaliert der Fall, wird ein Manager benachrichtigt?
- Können SLA-Ziele je nach Tageszeit, Wochentag oder Personalbestand angepasst werden?
- Wie wird dem Kunden die Wartezeit während der Überprüfung mitgeteilt?
Die Priorisierung der Warteschlange ist wichtig. Eine „First-In-First-Out“-Warteschlange behandelt eine Rückerstattungsanfrage genauso wie eine Produktfrage, auch wenn bei der Rückerstattung ein höheres Risiko besteht. Prioritätswarteschlangen leiten dringende Fälle schneller weiter, können jedoch Elemente mit niedrigerer Priorität blockieren, wenn sie nicht verwaltet werden. Einige Plattformen verwenden gewichtete Warteschlangen, Alterungsregeln, die die Priorität im Laufe der Zeit erhöhen, oder Eskalation, wenn die Wartezeit einen Schwellenwert überschreitet.
- Beispiel: Eine Plattform bietet drei SLA-Stufen: kritisch (Reaktionszeit 15 Minuten), hoch (2 Stunden) und normal (24 Stunden). Zu den kritischen Fällen gehören Sicherheitsbedenken, verärgerte VIPs und regulatorische Probleme. Zu den häufigsten Fällen zählen Abrechnungsstreitigkeiten und Kontoänderungen. Zu den Normalfällen gehören Routinefragen und Feedback.
- Beispiel: Wenn ein Fall länger als die Hälfte seines SLA-Ziels in der Warteschlange bleibt, benachrichtigt das System einen Vorgesetzten und bietet die Option zur Neuzuweisung oder Beschleunigung an.
- Beispiel: Ein Kunde sieht in einem Live-Chat eine geschätzte Wartezeit und eine Nachricht über die Position in der Warteschlange, während sein Fall auf die Genehmigung durch den Prüfer wartet. Wenn die Wartezeit mehr als fünf Minuten beträgt, bietet das System an, stattdessen per E-Mail fortzufahren.
- Kein Beispiel: Alle Fälle gelangen in die gleiche Warteschlange, ohne Priorisierung, ohne SLA-Ziele, ohne Einblick in die Wartezeit und ohne Kommunikation mit dem Kunden über Verzögerungen.
Das SLA-Design hängt auch mit der Personalausstattung zusammen. Wenn eine Warteschlange ständig Ziele verfehlt, sollte die Plattform dies als Kapazitätsproblem erkennen und nicht verbergen. Prüfer-Dashboards sollten die Warteschlangentiefe, die durchschnittliche Wartezeit und das Risiko von SLA-Verstößen anzeigen, damit Personalentscheidungen proaktiv getroffen werden können.
Fragen, die in Demos gestellt werden sollten:
- Können wir unterschiedliche SLA-Ziele nach Priorität, Kundensegment oder Problemtyp konfigurieren?
- Wie werden SLA-Verstöße erkannt und kommuniziert?
- Können wir die Wartezeiten in der Warteschlange und das SLA-Risiko in den Prüfer-Dashboards sehen?
- Was erlebt der Kunde, während er auf eine Bewertung wartet?
- Kann das System automatisch eskalieren oder Vorgesetzte benachrichtigen, wenn SLAs gefährdet sind?
- Wie geht die Plattform mit SLAs über alle Kanäle hinweg um: Chat, E-Mail, Messaging?
Zu überprüfende Quellen
Verwenden Sie diese Referenzen, um den Begriff zu verstehen und die Angaben der Anbieter zu Drucktests zu machen. Produktspezifische Details müssen noch anhand aktueller Lieferantenmaterialien überprüft werden.
FAQ
Häufige Fragen
Ist „Mensch in der Schleife“ dasselbe wie „Menschenübergabe“?
Nicht ganz. Übergabe bedeutet normalerweise, dass ein Gespräch an eine Person übergeben wird. Human in the Loop kann auch Genehmigungstore, Überprüfungswarteschlangen, Ausnahmebehandlung und menschliche Kontrolle umfassen, bevor eine automatisierte Aktion abgeschlossen wird.
Macht der Mensch in der Schleife einen KI-Agenten sicher?
Es hilft beim Risikomanagement, ist jedoch kein vollständiges Sicherheitssystem. Käufer sollten dennoch Berechtigungen, Tests, Prüfprotokolle, Fallback-Verhalten und die Häufigkeit, mit der eine menschliche Überprüfung tatsächlich ausgelöst wird, bewerten.
Wann sollte eine menschliche Überprüfung obligatorisch sein?
Eine obligatorische Überprüfung ist am nützlichsten für unumkehrbare Maßnahmen, sensible Kundenprobleme, Kontoänderungen, Rückerstattungen, Rechnungsstreitigkeiten, Antworten mit geringem Vertrauen und Arbeitsabläufe, bei denen Richtlinien- oder Compliance-Risiken von Bedeutung sind.
Was ist der Unterschied zwischen Human in the Loop und Human on the Loop?
„Human in the Loop“ bedeutet normalerweise, dass eine Person am Entscheidungsweg beteiligt ist, bevor eine Reaktion oder Aktion abgeschlossen ist. „Mensch auf dem Laufenden“ bedeutet normalerweise, dass eine Person das System überwacht und eingreifen kann, das System jedoch weiterlaufen kann, sofern es nicht gestoppt wird. Bei sensiblen Arbeitsabläufen sollten Käufer fragen, ob Menschen das Ergebnis ändern können, bevor es den Kunden oder das Aufzeichnungssystem erreicht.
Was sollte ein menschlicher Prüfer sehen, bevor er eine Aktion eines KI-Agenten genehmigt?
Ein Prüfer sollte den Gesprächsverlauf, den Kunden- oder Kontokontext, die abgerufenen Quellen, die vom Agenten vorgeschlagene Antwort oder Aktion, den Grund für die Eskalation des Falls und alle relevanten Risikomarkierungen sehen. Wenn der Prüfer nur ein Transkript ohne Quellennachweis oder vorgeschlagene Maßnahmen sieht, kann die Genehmigung eher zu einer Vermutung als zu einer sinnvollen Kontrolle werden.
Kann der Mensch in der Schleife den Support verlangsamen?
Ja. Wenn jeder Fall mit geringem Risiko eine Genehmigung erfordert, kann die menschliche Überprüfung zu Warteschlangen, Verzögerungen und Personalbedarf führen. Das Ziel besteht darin, eine Überprüfung dort zu platzieren, wo eine Beurteilung das Ergebnis verändert: sensible Handlungen, wenig vertrauenswürdige Antworten, VIP-Kunden, verärgerte Kunden, Rechnungsstreitigkeiten oder irreversible Änderungen. Ein gutes Warteschlangendesign hält die Routinearbeit in Bewegung und schützt gleichzeitig Fälle mit hohem Risiko.
Wie misst man die Human-in-the-Loop-Qualität?
Zu den nützlichen Messgrößen zählen das Volumen der Review-Warteschlange, die durchschnittliche Genehmigungszeit, die Override-Rate, die Rate verpasster Eskalationen, die Rate falscher Eskalationen, die Wartezeit des Kunden, die Zustimmung des Prüfers, in der Qualitätssicherung gefundene Vorfälle und die Häufigkeit, mit der das Review-Feedback Eingabeaufforderungen, Quellen oder Workflow-Regeln verbessert. Diese Kennzahlen zeigen, ob die Aufsicht die Ergebnisse verbessert oder nur für zusätzliche Reibung sorgt.
Was sind häufige Fehlermodi durch den Menschen im Regelkreis?
Zu den häufigsten Fehlern gehören abgesegnete Genehmigungen, überlastete Überprüfungswarteschlangen, unklare Eigentumsverhältnisse, Prüfer ohne ausreichenden Kontext, zu weit gefasste oder zu enge Eskalationsregeln und eine Nachbearbeitungsprotokollierung, die als Echtzeitkontrolle dargestellt wird. Käufer sollten den Review-Pfad mit realistischen Randfällen testen, bevor sie ihm in der Produktion vertrauen.
Wer sollte über Human-in-the-Loop-Workflows verfügen?
Das Eigentum muss normalerweise geteilt werden. Betriebs- oder Supportleiter sollten für die Workflow-Qualität und Überprüfungsregeln verantwortlich sein, während IT- oder Sicherheitsteams für Berechtigungen, Protokollierung und Systemzugriff zuständig sind. Der Schlüssel besteht darin, zu benennen, wer Eskalationsschwellenwerte ändern, die Automatisierung pausieren, Prüfer schulen und entscheiden kann, wann ein Arbeitsablauf von der obligatorischen Genehmigung zur stichprobenartigen Qualitätssicherung übergeht.
Was ist eine KI-gestützte Überprüfung und hilft oder schadet sie der Aufsicht?
KI-gestützte Überprüfung bedeutet, dass die Plattform Änderungen vorschlägt, die Relevanz der Quelle hervorhebt oder Vertrauensindikatoren anzeigt, um Prüfern zu helfen, schneller zu arbeiten. Es hilft, wenn Vorschläge die kognitive Belastung reduzieren, ohne zum Mitmachen anzuregen. Wenn Gutachter KI-Vorschläge genehmigen, ohne sie zu lesen, oder wenn Vorschläge häufig falsch sind und zu Rauschen werden, kann die Funktion die Übersicht beeinträchtigen. Käufer sollten testen, ob die Vorschläge ihre Begründung erläutern, und nachverfolgen, wie oft Rezensenten sie akzeptieren oder überschreiben.
Wie funktioniert intelligentes Routing für die menschliche Überprüfung?
Intelligentes Routing nutzt Signale wie Konfidenzschwellen, Kundenstufe, Themenklassifizierung und Stimmung, um zu entscheiden, welcher Mensch einen Fall bearbeiten soll und ob dieser menschliche Aufmerksamkeit benötigt. Ziel ist es, Fälle mit Gutachtern zusammenzubringen, die über das richtige Fachwissen, die richtige Verfügbarkeit und die richtige Autorität verfügen. Käufer sollten sich fragen, welche Signale Routing-Entscheidungen beeinflussen, ob Schwellenwerte anpassbar sind und wie sich das Routing basierend auf dem Verhalten der Prüfer im Laufe der Zeit anpasst.
Verbessern menschliche Korrekturen den KI-Agenten im Laufe der Zeit?
Das ist möglich, wenn die Plattform über eine Feedbackschleife verfügt. Kontinuierliches Lernen aus Korrekturen bedeutet, dass das System Änderungen von Prüfern erfasst, Muster analysiert und Eingabeaufforderungen, Quellen oder Verhalten aktualisiert. Ohne Rückkopplungsschleife sind Korrekturen einmalige Korrekturen, die in einem Protokoll verschwinden. Käufer sollten sich fragen, wie Korrekturen in das System zurückfließen, ob Teams aggregierte Muster erkennen können und ob vorgeschlagene Änderungen vor der Produktivsetzung genehmigt werden müssen.
Wie verhindern Sie, dass die Ermüdung der Prüfer die Qualität beeinträchtigt?
Die Ermüdung der Prüfer zeigt sich in inkonsistenten Entscheidungen, höheren Zustimmungsraten und einem Qualitätsabfall nach langen Sitzungen. Plattformen können dabei helfen, indem sie Metriken zur Zustimmung der Gutachter verfolgen, Arbeitsbelastungsgrenzen festlegen, Spitzen bei der Genehmigungsrate erkennen, die auf Sparmaßnahmen hindeuten, und Fälle mit hohem Risiko auf die Gutachter verteilen. Käufer sollten fragen, ob die Plattform Qualitätsmetriken pro Prüfer anzeigt und ob sie Kalibrierung, QA-Stichprobenentnahme und Arbeitsbelastungsgrenzen unterstützt.
Welche SLA-Ziele sollten wir für die menschliche Überprüfung festlegen?
SLA-Ziele hängen vom Kontext ab: Kanal, Kundenstufe, Problemtyp und Risikostufe. Bei einem Abrechnungsstreit kann eine Beantwortung innerhalb von zwei Stunden erforderlich sein, während bei einer Routinefrage möglicherweise vierundzwanzig Stunden vergehen. Ein effektives SLA-Design umfasst Prioritätsstufen, Warteschlangenalterungsregeln, Benachrichtigungen bei Verstößen und Kundenkommunikation während der Wartezeit. Käufer sollten sich fragen, ob die Plattform konfigurierbare SLAs nach Segmenten unterstützt, das SLA-Risiko in Prüfer-Dashboards anzeigt und Verstöße ordnungsgemäß behandelt.