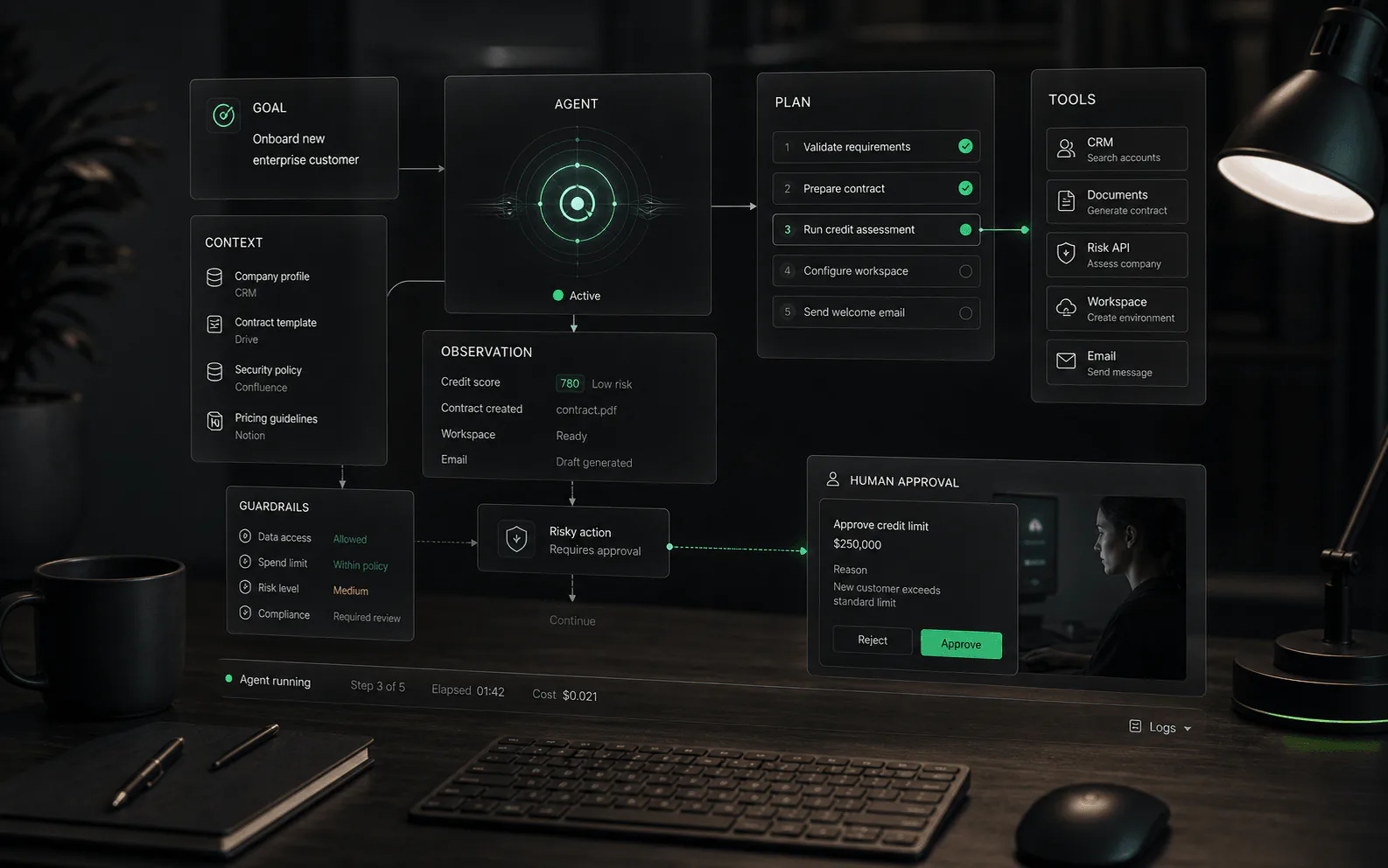
Was RAG macht
RAG verbindet Erzeugung mit Abruf. Anstatt ein Modell nur aufgrund seiner allgemeinen Schulung zu einer Antwort aufzufordern, durchsucht das System genehmigte Quellen, wählt relevante Passagen oder Aufzeichnungen aus und verwendet diesen Kontext, um eine Antwort zu erstellen. In KI-Agent-Produkten können diese Quellen je nach Unterstützung der Plattform Help Center, interne Dokumente, Produkthandbücher, Richtlinienseiten, CRM-Datensätze, Bestelldaten oder andere Geschäftssysteme umfassen.
So funktioniert RAG
- Aufnahme: Genehmigte Quellen werden aus Dokumenten, Hilfezentren, Datenbanken, APIs oder anderen Repositorys gesammelt.
- Vorbereiten: Der Inhalt wird analysiert, bereinigt, in aussagekräftige Abschnitte aufgeteilt, mit Tags versehen, mit Berechtigungen versehen und zum Abruf indiziert.
- Abrufen: Wenn ein Benutzer eine Frage stellt, sucht das System mithilfe von Stichwortsuche, Vektorsuche, Hybridsuche, Reranking oder einem anderen Abrufansatz nach relevantem Quellmaterial.
- Erweitern: Der ausgewählte Kontext wird mit Anweisungen zu seiner Verwendung in die Modelleingabeaufforderung eingefügt.
- Generieren: Das Modell schreibt eine Antwort unter Verwendung des abgerufenen Kontexts, idealerweise mit Sichtbarkeit der Quelle für Prüfer oder Benutzer, sofern angemessen.
- Verbessern: Fehlgeschlagene Abfragen und korrigierte Antworten werden in die Quellhygiene, die Abrufoptimierung und die Bewertungssätze zurückgeführt.
Warum es für KI-Agenten wichtig ist
RAG ist eine der Hauptmethoden, mit denen ein KI-Agent geschäftsspezifisch wird. Ein Supportmitarbeiter, der die aktuelle Rückerstattungsrichtlinie, Garantieregel, Preisseite, Produktbeschränkung oder den Kontokontext nicht abrufen kann, wird oft fließende, aber unzuverlässige Antworten geben. Eine gute Recherche macht das System nicht perfekt, aber sie gibt dem Agenten eine bessere Chance, auf der Grundlage des Materials zu antworten, dem das Unternehmen tatsächlich vertraut.
RAG kann auf mehreren Ebenen versagen
- Quellenfehler: Die richtige Antwort fehlt, ist veraltet, dupliziert, widersprüchlich oder in einer Weise geschrieben, die der Rechercheur nicht verwenden kann.
- Indexierungsfehler: Der Inhalt wurde schlecht aufgeteilt, falsch getaggt, ohne nützliche Metadaten eingebettet oder nach einem Update nicht aktualisiert.
- Fehler beim Abrufen: Das System findet die falsche Passage, übersieht ein Synonym, ordnet alten Inhalt höher als den aktuellen Inhalt oder ruft Material ab, das der Benutzer nicht sehen sollte.
- Erdungsfehler: Das Modell empfängt den richtigen Kontext, ignoriert ihn jedoch, überdehnt ihn oder liest ihn falsch.
- Erleben Sie Misserfolg: Die Antwort klingt zuversichtlich, gibt den Prüfern jedoch keine Quellenspur, kein Unsicherheitssignal oder keinen Eskalationspfad vor.
Die Qualität hängt nicht nur vom Datei-Upload ab
- Qualität der Quelle: Veraltete, doppelte, widersprüchliche oder schlecht strukturierte Dokumente führen zu schlechten Antworten.
- Chunking und Indexierung: Das System muss Wissen so aufteilen und speichern, dass die Bedeutung erhalten bleibt.
- Abrufqualität: Der Agent muss den richtigen Kontext für komplizierte Fragen aus der realen Welt finden, nicht nur für exakte Schlüsselwortübereinstimmungen.
- Umgang mit Berechtigungen: Private oder rollenbeschränkte Inhalte sollten nicht in Antworten für den falschen Benutzer erscheinen.
- Rückfallverhalten: Das System sollte wissen, wenn Quellen fehlen, schwach sind oder widersprüchlich sind, anstatt Gewissheit zu erfinden.
- Überprüfungsworkflow: Teams benötigen eine Möglichkeit, schlechte Antworten zu identifizieren und das Quellmaterial oder die Abrufregeln zu korrigieren.
Was Käufer testen sollten
- Stellen Sie Fragen, bei denen die Antwort in einer anerkannten Quelle und nirgendwo anders zu finden ist.
- Stellen Sie Fragen, wenn zwei Dokumente in Konflikt stehen, und prüfen Sie, ob der Agent Unsicherheit bemerkt.
- Fragen Sie nach einer veralteten Richtlinie und prüfen Sie, ob die neueste Quelle gewinnt.
- Stellen Sie berechtigungsrelevante Fragen und stellen Sie sicher, dass eingeschränkte Inhalte auch weiterhin eingeschränkt bleiben.
- Stellen Sie Fragen ohne verlässliche Quelle und prüfen Sie, ob der Agent sagt, er wisse es nicht, oder eskaliert.
- Überprüfen Sie, ob Zitate oder Quellenausschnitte für die Qualitätssicherung für Menschen verfügbar sind.
Auswertungsdatensatz für RAG-Demos
Eine seriöse RAG-Demo sollte vor der Beschaffung ein kleines, aber realistisches Testset verwenden. Schließen Sie Fragen mit einer eindeutigen Quelle ein, Fragen, die zwei Quellen erfordern, Fragen mit veralteten Fallen, Fragen mit eingeschränktem Inhalt, Fragen, die keine Antwort liefern sollten, und Fragen, die die Sprache des Kunden anstelle der internen Terminologie verwenden. Das Ziel besteht darin, die Antwortkompetenz von der Abrufqualität zu trennen.
Konkrete Beispiele und Nicht-Beispiele
- Beispiel: Ein Supportmitarbeiter ruft die aktuelle Garantierichtlinie ab, gibt intern die entsprechende Quelle an und antwortet nur innerhalb der Grenzen dieser Richtlinie.
- Beispiel: Ein interner Betriebsagent durchsucht eine Verfahrensbibliothek, bevor er den nächsten Schritt für eine Mitarbeiteranfrage entwirft.
- Beispiel: Ein E-Commerce-Agent ruft den auftragsspezifischen Kontext und die Produktdokumentation ab, bevor er erklärt, welche Informationen ein Mensch benötigt, um eine Retoure zu prüfen.
- Kein Beispiel: Ein Modell antwortet aus dem allgemeinen Gedächtnis, ohne genehmigte Geschäftsquellen zu überprüfen.
- Kein Beispiel: Ein Anbieter lädt Dokumente einmal hoch, bietet jedoch keinen Aktualisierungsprozess, keine Berechtigungskontrollen, keine Quellensichtbarkeit oder keine Fehlerberichterstattung.
RAG versus Modelltraining
RAG ist nicht dasselbe wie das Trainieren eines Modells. Das Training verändert das Modellverhalten durch zusätzliches Lernen. RAG ruft externe Informationen zur Reaktionszeit ab. Für Käufer ist diese Unterscheidung wichtig, da RAG häufig aktualisierte Geschäftsinhalte schneller wiedergeben kann, sie hängt jedoch auch stark von der Aktualität der Quelle, der Indexierung, den Berechtigungen und der Abrufqualität ab.
RAG versus langer Kontext
Modelle mit langem Kontext können große Textmengen in einer Eingabeaufforderung akzeptieren, aber das ist nicht automatisch RAG. RAG impliziert selektiven Abruf: Das System wählt vor der Generierung relevantes Material aus einem größeren Quellsatz aus. Das Einbetten einer großen Datei in den Kontext kann für engere Aufgaben nützlich sein, aber es allein löst nicht die Aktualität der Quelle, Berechtigungen, Rangfolge, Konfliktlösung oder wiederkehrende Wissensvorgänge.
Rote Fahnen
Seien Sie skeptisch, wenn ein Anbieter das Hochladen einer PDF-Datei als Beweis für eine zuverlässige Wissensvermittlung ansieht. Achten Sie auch darauf, dass es keine Quellensichtbarkeit, keine Aktualisierungskontrollen, kein Berechtigungsmodell, keine Möglichkeit zum Umgang mit widersprüchlichen Dokumenten, keine Berichterstattung über unbeantwortete Fragen und keinen Prozess zur Verbesserung schlechter Abrufe nach dem Start gibt.
Zu überwachende Metriken
Die RAG-Qualität sollte über die Antwortkompetenz hinaus gemessen werden. Zu den nützlichen Signalen gehören die Trefferquote beim Abrufen von Fragen mit bekannten Antworten, die Aktualität der Quelle, die Rate ungelöster Abfragen, die Zitiergenauigkeit, Fehler bei der Berechtigung, Vorfälle mit widersprüchlichen Quellen, die Antwortkorrekturrate und die Anzahl fehlgeschlagener Fragen, die zu Wissensverbesserungen führen. Diese Maßnahmen tragen dazu bei, schwaches Quellmaterial von schwachem Abruf und schwacher Erzeugung zu trennen.
Wissensoperationen
RAG schafft ein fortlaufendes Wissensbetriebsproblem. Jemand muss entscheiden, welche Quellen genehmigt werden, Duplikate entfernen, veraltetes Material archivieren, Richtlinienkonflikte lösen und Fragen überprüfen, die der Agent nicht beantworten konnte. Käufer sollten sich fragen, ob diese Schleife für den Support, den Produktbetrieb, die Dokumentation oder die IT zuständig ist. Ohne einen namentlich genannten Eigentümer nimmt die Abrufqualität in der Regel ab, wenn sich Produkte, Richtlinien und Kundensprache ändern.
Eigentum nach dem Start
Der Eigentümer der RAG-Qualität sollte die Befugnis haben, Quellmaterial zu ändern und nicht nur Analysen zu lesen. Wenn Support-Teams wiederholt Fehler beim Abrufen feststellen, Dokumentationseigentümer die Artikel jedoch nicht schnell aktualisieren können, schlägt der Agent weiterhin auf die gleiche Weise fehl. Eine nützliche Betriebsschleife verbindet fehlgeschlagene Fragen, Quellkorrekturen, Neuindizierung, Regressionstests und die Freigabe durch Prüfer, bevor das aktualisierte Wissen in der Produktion als vertrauenswürdig eingestuft wird.
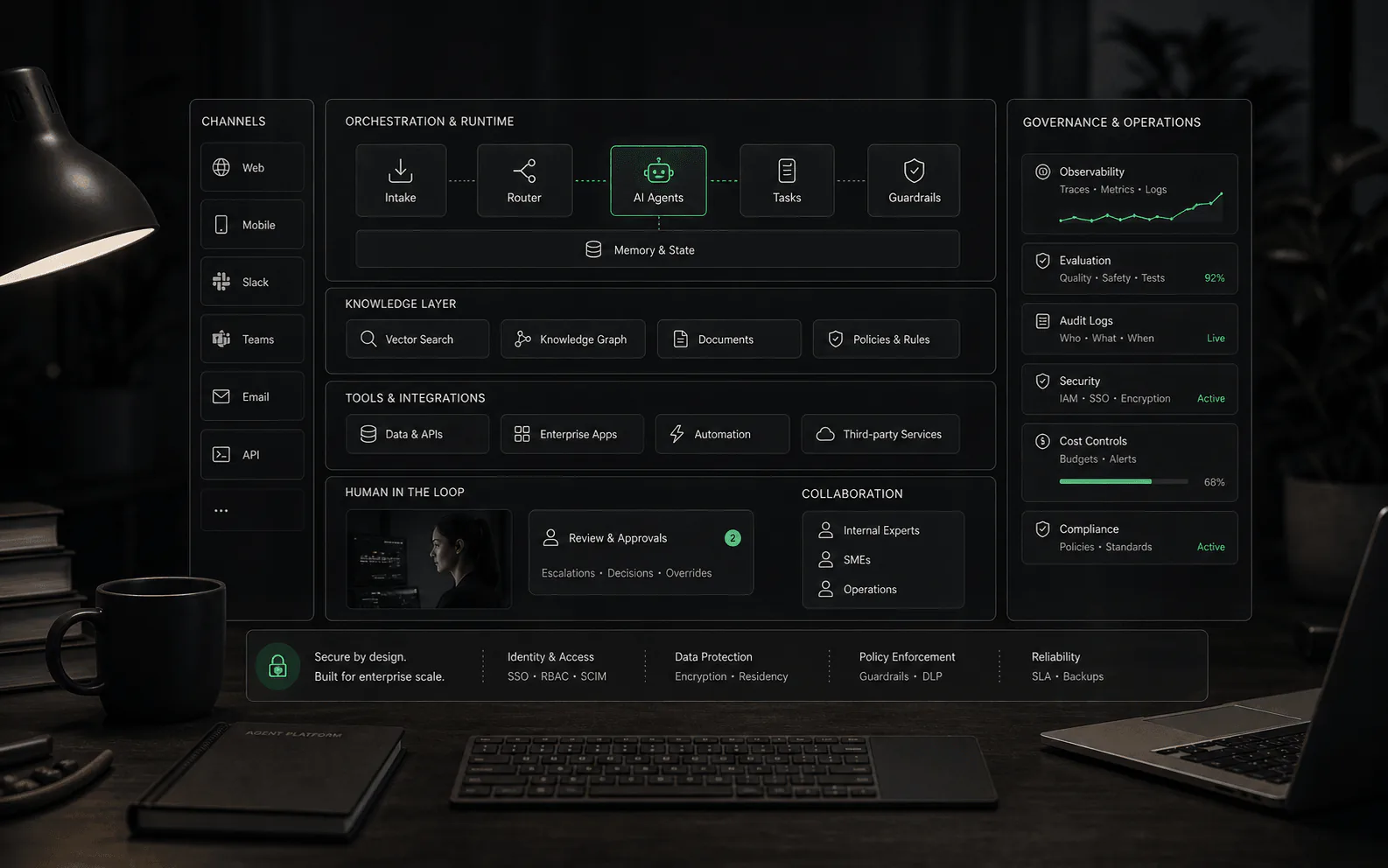
Agentischer RAG
Agentic RAG erweitert das traditionelle RAG, indem es dem KI-Agenten ermöglicht, mehrere Abrufschritte durchzuführen, Tools aufzurufen und seine Suche auf der Grundlage von Zwischenergebnissen zu verfeinern. Anstelle eines einzigen Durchlaufs „Abrufen und dann generieren“ kann der Agent entscheiden, erneut zu suchen, verschiedene Abfragen auszuprobieren, APIs aufzurufen oder Informationen aus mehreren Quellen durch iteratives Denken zu kombinieren. Dies ist für KI-Agentenplattformen wichtig, da komplexe geschäftliche Fragen häufig eine mehrstufige Untersuchung erfordern: Ein Supportmitarbeiter ruft möglicherweise zunächst die Rückerstattungsrichtlinie ab, überprüft dann den Bestellstatus des Kunden über die API und ruft dann produktspezifische Garantiebedingungen ab, bevor er antwortet.
- Iterativer Abruf: Der Agent kann mehrere Abfragen stellen, basierend auf dem, was er findet, verfeinern und entscheiden, wann die Suche beendet werden soll.
- Tool-Erweiterung: Der Agent kombiniert den Dokumentenabruf mit Datenbanksuchen, API-Aufrufen und Berechnungen, nicht nur mit statischem Text.
- Selbstkorrektur: Wenn das anfängliche Abrufen schlechte Ergebnisse liefert, kann der Agent die Aussage umformulieren, erweitern oder umschwenken, anstatt zu halluzinieren.
- Erinnerung über Gesprächsrunden hinweg: Agentisches RAG behält häufig den Kontext früherer Gesprächsrunden bei und ermöglicht so Folgefragen, ohne alles erneut abrufen zu müssen.
- Planen und ausführen: Einige Agenten-RAG-Systeme planen vor der Ausführung eine Abrufstrategie und reduzieren so den verschwendeten Aufwand auf irrelevanten Pfaden.
Für Käufer, die KI-Agentenplattformen evaluieren, werden Agenten-RAG-Funktionen wichtig, wenn der Anwendungsfall komplexe, mehrstufige Untersuchungen und nicht einfache Antworten im FAQ-Stil umfasst. Fragen Sie die Anbieter, ob der Abruf in einem Durchgang oder iterativ erfolgt, ob der Agent Tools während des Abrufs aufrufen kann und wie das System mit Fällen umgeht, in denen die erste Suche nichts Nützliches zurückgibt. Ein Single-Pass-RAG-System wird mit Fragen wie „Warum wurde mein Konto diesen Monat zweimal belastet?“ zu kämpfen haben. wobei die Antwort das Abrufen von Abrechnungsrichtlinien, das Überprüfen des Transaktionsverlaufs über die API und den Vergleich von Daten erfordert.
Hybridsuche
Die Hybridsuche kombiniert mehrere Abrufmethoden – typischerweise Schlüsselwort (BM25), Vektorähnlichkeit und manchmal semantisches Reranking –, um die Abrufqualität zu verbessern. Bei der reinen Stichwortsuche fehlen Synonyme und konzeptionelle Übereinstimmungen. Bei der reinen Vektorsuche können genaue Übereinstimmungen fehlen oder durch das Einbetten von Rauschen beeinträchtigt werden. Die Hybridsuche reduziert beide Fehlermodi, indem sie die Ergebnisse mehrerer Methoden in eine Rangfolge bringt und sie intelligent zusammenführt.
- Stichwortsuche (BM25): Entspricht genauen Begriffen und Phrasen. Stark für Produktnamen, SKUs, Fehlercodes und spezifische Kennungen. Schwach für konzeptionelle Fragen oder paraphrasierte Absichten.
- Vektorsuche (semantisch): Gleicht die Bedeutung durch Vergleich der Einbettungsvektoren ab. Stark für paraphrasierte Fragen, konzeptionelle Übereinstimmungen und sprachübergreifendes Abrufen. Schwach für genaue Bezeichner und manchmal verwirrt durch ähnlich klingende Konzepte.
- Reranking: Ein Modell der zweiten Stufe bewertet die ersten Ergebnisse sorgfältiger, häufig unter Verwendung eines Cross-Encoders, der Abfrage und Dokument gemeinsam auswertet. Durch das Reranking wird die Präzision auf Kosten der Latenz verbessert.
- Fusion: Ergebnisse aus der Stichwort- und Vektorsuche werden mithilfe der reziproken Rangfusion oder der erlernten Bewertung kombiniert und anschließend optional neu eingestuft.
Für Käufer von KI-Agenten ist die Hybridsuche oft eine Frage wert. Ein Anbieter, der sich nur auf die Vektorsuche verlässt, übersieht möglicherweise genau die Übereinstimmungen, die ein Kunde erwarten würde. Ein Anbieter, der sich nur auf die Suche nach Schlüsselwörtern verlässt, kann bei Abfragen in natürlicher Sprache, die einen anderen Wortlaut als die Dokumentation verwenden, scheitern. Stellen Sie Demo-Fragen, die konzeptionelle und konkrete Anforderungen vermischen: „Was ist der Unterschied zwischen den Preisstufen Pro und Enterprise?“ (erfordert das Suchen und Vergleichen von Preisseiten) oder „Wie behebe ich Fehler 503?“ (erfordert den Abgleich des Fehlercodes bei gleichzeitigem Verständnis des Kontexts).
Multimodaler Abruf
Der multimodale Abruf erweitert RAG über Text hinaus und umfasst Bilder, Tabellen, Videos, Audio und strukturierte Daten. Geschäftswissen ist oft multimodal: Produkthandbücher enthalten Diagramme und Tabellen, Help Center enthalten Screenshots, Support-Tickets enthalten Fotos und Richtliniendokumente enthalten eingebettete Diagramme. Einem reinen Text-RAG-System entgehen Informationen, die in Nicht-Textformaten gespeichert sind, was zu unvollständigen oder falschen Antworten führt.
- Bilder: Abrufen von Diagrammen, Screenshots, Produktfotos und Fehler-Screenshots. Erfordert bildverarbeitungsfähige Einbettungen oder OCR-Pipelines.
- Tabellen: Extrahieren strukturierter Daten aus PDFs, Tabellenkalkulationen und HTML-Tabellen. Tabellen enthalten oft Preise, Spezifikationen und Vergleichsdaten, die durch Text-Chunking zerstört werden.
- Video und Audio: Indizierung von Zeitstempeln, Transkripten und visuellen Frames aus Schulungsvideos, Webinaren und aufgezeichneten Supportanrufen.
- Strukturierte Daten: Abfragen von Datenbanken, APIs und Wissensgraphen neben unstrukturierten Dokumenten. Ermöglicht Antworten, die narrative Erklärungen mit Live-Daten kombinieren.
Für Käufer ist multimodaler Support wichtig, wenn die Wissensdatenbank Nicht-Text-Assets umfasst. Fragen Sie, ob die Plattform PDFs mit eingebetteten Bildern indizieren und daraus abrufen kann, ob Tabellen als strukturierte Daten erhalten bleiben und nicht in inkohärente Textblöcke zerlegt werden und ob bildbasierte Abfragen (wie „Zeigen Sie mir den Schaltplan für Modell X“) unterstützt werden. Eine Plattform, die nur Text indiziert, liefert unvollständige Antworten für Produkte mit visueller Dokumentation, Montageanleitungen mit Diagrammen oder Support-Tickets mit Fehler-Screenshots.
Chunking-Strategien
Beim Chunking werden Dokumente vor der Indizierung in abrufbare Einheiten aufgeteilt. Die Größe und Überlappung der Stücke wirkt sich erheblich auf die Abrufqualität aus. Kleine Abschnitte bewahren bestimmte Details, verlieren jedoch den Kontext. Große Blöcke bewahren den Kontext, verwässern jedoch die Relevanz und verbrauchen das Budget für das Kontextfenster. Durch Überlappung wird sichergestellt, dass relevante Passagen nicht an den Grenzen abgeschnitten werden. Beim semantischen Chunking wird versucht, die Aufteilung an Konzeptgrenzen vorzunehmen und nicht an willkürlichen Zeichen- oder Satzgrenzen.
- Chunk-Größe: typischerweise 200–1000 Token. Kleinere Abschnitte verbessern die Präzision bei bestimmten Fragen, lassen jedoch möglicherweise den umgebenden Kontext außer Acht. Größere Abschnitte liefern Kontext, rufen aber möglicherweise irrelevantes Material ab.
- Überlappung: Eine Überlappung von 10–20 % zwischen den Abschnitten trägt dazu bei, dass relevante Passagen über die Abschnittsgrenzen hinausgehen. Keine Überschneidungen bergen die Gefahr, dass wichtige Informationen halbiert werden.
- Semantisches Chunking: Verwendet Satzeinbettungen oder -strukturen (Überschriften, Absätze, Abschnitte), um an Bedeutungsgrenzen statt an festen Größen aufzuteilen. Behält kohärente Ideen bei, erfordert jedoch mehr Verarbeitung.
- Eltern-Kind-Chunking: Ruft kleine Blöcke aus Relevanzgründen ab, lädt jedoch größere übergeordnete Blöcke aus Kontextgründen. Bringt Präzision und Kontext in Einklang.
- Tabellen- und Code-Chunking: erfordert eine besondere Behandlung. Tabellen sollten oft in Einheiten oder Zeilen unterteilt werden, wobei die Überschriften erhalten bleiben. Codeblöcke benötigen einen Funktionskontext.
Die Chunking-Qualität erklärt oft, warum dieselben Dokumente auf verschiedenen Plattformen unterschiedliche Antworten liefern. Fragen Sie Käufer, wie die Plattform das Chunking handhabt, ob es Kontrollen für Blockgröße und Überlappung gibt, ob Tabellen und Code speziell behandelt werden und ob das Chunking pro Dokumenttyp optimiert werden kann. Ein Anbieter, der alle Dokumente gleich behandelt, wird mit gemischten Inhaltstypen zu kämpfen haben: Ein 50-seitiges PDF-Richtlinienhandbuch erfordert eine andere Aufteilung als eine Reihe kurzer FAQ-Einträge.
Überlegungen zum Einbetten von Modellen
Einbettungsmodelle konvertieren Text für die semantische Suche in Vektordarstellungen. Die Wahl des Einbettungsmodells wirkt sich auf die Abrufqualität, die Sprachabdeckung, die Domänenspezifität und die Kosten aus. Neuere Modelle übertreffen oft ältere, aber der Wechsel des Einbettungsmodells erfordert eine Neuindizierung des gesamten Korpus. Käufer sollten verstehen, welches Einbettungsmodell eine Plattform verwendet, wie oft sie aktualisiert wird und was passiert, wenn Modelle aktualisiert werden.
- Modellqualität: Einbettungsmodelle unterscheiden sich in ihrer Fähigkeit, semantische Ähnlichkeiten zu erfassen, verschiedene Sprachen zu verarbeiten und domänenspezifische Terminologie darzustellen. Ein Modell, das auf allgemeine Webtexte trainiert wird, kann mit medizinischer, rechtlicher oder technischer Dokumentation Schwierigkeiten haben.
- Modellgröße und -geschwindigkeit: Größere Modelle erzeugen oft bessere Einbettungen, kosten aber mehr in der Ausführung. Beim Abruf großer Datenmengen kommt es auf den Kompromiss zwischen Qualität und Latenz an.
- Domänenanpassung: Einige Plattformen ermöglichen die Feinabstimmung von Einbettungen in Domänendaten. Dies kann die Suche nach Fachvokabular verbessern, erhöht jedoch die Komplexität und die Wartungskosten.
- Mehrsprachige Unterstützung: Einbettungsmodelle variieren in der Sprachabdeckung. Ein Modell, das hauptsächlich auf Englisch trainiert wurde, kann in anderen Sprachen schlecht abschneiden, was sich auf globale Bereitstellungen auswirkt.
- Modellaktualisierungen und Neuindizierung: Wenn einbettende Modelle aktualisiert oder ersetzt werden, müssen alle Dokumente neu eingebettet werden. Fragen Sie, ob Upgrades automatisch erfolgen, ob sie Ausfallzeiten verursachen und ob Rückgänge bei der Abrufqualität überwacht werden.
Für Käufer, die Plattformen bewerten, ist die Wahl des Einbettungsmodells oft unsichtbar, aber wirkungsvoll. Fragen Sie, welches Einbettungsmodell verwendet wird, ob es die benötigten Sprachen unterstützt, ob eine Domänenanpassung verfügbar ist und was passiert, wenn das Modell aktualisiert wird. Bei einer Plattform, die Sie an ein veraltetes Einbettungsmodell bindet, wird sich die Abrufqualität im Vergleich zu Mitbewerbern, die ein Upgrade durchführen, verschlechtern.
Modelle neu einordnen
Das Reranking ist ein Abrufschritt der zweiten Stufe, der die ersten Ergebnisse mithilfe eines leistungsfähigeren (normalerweise encoderübergreifenden) Modells neu bewertet. Nachdem der erste Abruf über die Schlüsselwort- oder Vektorsuche etwa 50–100 Kandidatenpassagen ergeben hat, wertet ein Reranker gemeinsam jedes Abfrage-Dokument-Paar aus, um eine genauere Relevanzbewertung zu erzielen. Durch das Reranking wird die Präzision verbessert, allerdings erhöht sich die Latenz.
- Cross-Encoder: Das Reranking-Modell sieht sowohl Abfrage als auch Dokument zusammen und kann so Interaktionen erfassen, die Bi-Encoder-Einbettungsmodellen entgehen. Dies führt zu besseren Relevanzwerten, ist aber langsamer.
- Reranking-APIs: Einige Plattformen verwenden externe Reranking-APIs (Cohere, Jina, Voyage usw.), während andere Reranking-Modelle intern hosten. Eine extern gehostete Neubewertung kann zu Problemen mit der Latenz und der Datenübertragung führen.
- Top-K-Auswahl: Das Reranking wird normalerweise auf die ersten 20–100 ersten Ergebnisse angewendet. Nach der Neuordnung werden nur die obersten an das Generationsmodell übergeben.
- Kompromiss zwischen Qualität und Latenz: Eine Neubewertung verbessert die Antwortrelevanz, erhöht aber die Latenz pro Abfrage um 50–500 ms. Für Echtzeitunterstützung muss dieser Kompromiss bewertet werden.
- Kosten: Das Reranking ist rechenintensiver als das erste Abrufen. Bei hochvolumigen Systemen summieren sich die Kosten für die Neubewertung jeder Abfrage.
Für Käufer ist das Reranking eine Möglichkeit, gezielt nachzufragen. Eine Plattform, die nur den anfänglichen Abruf durchführt, kann bei mehrdeutigen Abfragen weniger relevante Ergebnisse liefern. Eine Plattform mit Reranking kann bessere Antworten liefern, jedoch mit höherer Latenz und höheren Kosten. Fragen Sie, ob eine Neubewertung enthalten ist, ob sie standardmäßig angewendet wird, ob es Kontrollen für den Zeitpunkt einer Neubewertung gibt und wie der Anbieter die Qualitätsverbesserung misst. Eine Demo, die bei sorgfältig ausgewählten Fragen gut aussieht, zeigt möglicherweise nicht den Wert einer Neubewertung bei chaotischen Abfragen aus der Praxis.
Zu überprüfende Quellen
Verwenden Sie diese Referenzen, um den Begriff zu verstehen und die Angaben der Anbieter zu Drucktests zu machen. Produktspezifische Details müssen noch anhand aktueller Lieferantenmaterialien überprüft werden.
FAQ
Häufige Fragen
Ist RAG dasselbe wie das Training eines KI-Modells?
Nein. Training verändert das Verhalten des Modells. RAG ruft externe Informationen zur Reaktionszeit ab, sodass die Qualität stark von den verbundenen Quellen, der Abruflogik und der Aktualität des indizierten Inhalts abhängt.
Verhindert RAG Halluzinationen?
Nein. RAG kann nicht unterstützte Antworten reduzieren, wenn die Abruf- und Quellqualität hoch ist, es garantiert jedoch keine Genauigkeit. Käufer benötigen weiterhin Ausweichverhalten, Quellenüberprüfung, Tests und menschliche Aufsicht für riskante Arbeitsabläufe.
Ist RAG dasselbe wie semantische Suche?
Nein. Die semantische Suche hilft dabei, relevante Informationen abzurufen, häufig durch Übereinstimmung mit der Bedeutung und nicht durch genaue Schlüsselwörter. RAG verwendet das Abrufen als einen Schritt in einem größeren Muster: relevanten Kontext abrufen, an ein generatives Modell übergeben und eine Antwort erstellen. Ein System kann eine semantische Suche ohne Generierung durchführen und Text generieren, ohne einen zuverlässigen Abruf durchzuführen.
Ist das Hochladen von Dokumenten auf einen Chatbot dasselbe wie bei RAG?
Nicht von alleine. Hochgeladene Dokumente können in einem RAG-System verwendet werden, wenn der Chatbot zum Zeitpunkt der Antwort relevante Passagen aus diesen Dokumenten abruft und sie als Kontext für die Generierung verwendet. Eine Schaltfläche zum Hochladen von Dateien beweist jedoch nicht, wie der Abruf funktioniert, ob die richtigen Passagen ausgewählt werden, ob die Quellen aktuell sind oder ob die Antwort im abgerufenen Material verankert bleibt. Für Käufer besteht der Test darin, den Abrufschritt, die Quellensichtbarkeit und das Fehlerverhalten zu überprüfen.
Wie unterscheidet sich RAG von der Feinabstimmung?
Durch die Feinabstimmung wird das Modellverhalten durch Training anhand zusätzlicher Beispiele oder Daten geändert. RAG ruft zur Antwortzeit externe Informationen ab und verwendet sie als Kontext für die Antwort. RAG eignet sich oft besser für die Änderung von Geschäftswissen, da Quellen ohne Umschulung aktualisiert werden können, die Qualität jedoch immer noch von Abruf, Berechtigungen und Quellenhygiene abhängt.
Was sollten Käufer in einer RAG-Demo testen?
Verwenden Sie Fragen mit einer eindeutigen Quelle, Fragen, die mehrere Quellen erfordern, veraltete Richtlinienfallen, berechtigungsrelevante Inhalte, von Kunden tatsächlich verwendete Synonyme und Fragen, bei denen die richtige Antwort unbekannt sein sollte. Fragen Sie nach den abgerufenen Quellen und nicht nur nach der endgültigen Antwort, damit Sie erkennen können, ob die Antwort fundiert oder nur fließend war.
Was führt dazu, dass RAG-Systeme falsche Antworten geben?
Falsche Antworten können aus veralteten Quellen, widersprüchlichen Dokumenten, schlechter Aufteilung, schwachem Abruf, fehlenden Metadaten, Berechtigungsfehlern, Kontextfensterbeschränkungen oder einem Modell stammen, das das abgerufene Material ignoriert. Das Debuggen von RAG erfordert die Trennung von Quellproblemen, Abrufproblemen, Erdungsproblemen und Generierungsproblemen, anstatt jeden Fehler als sofortiges Problem zu behandeln.
Wem soll RAG-Qualität nach der Markteinführung gehören?
RAG-Qualität braucht einen operativen Eigentümer mit der Befugnis, das Ausgangsmaterial zu verbessern. Supportvorgänge, Produktvorgänge, Dokumentation oder Wissensmanagement können für die Inhaltsqualität verantwortlich sein, während technische Teams für Indizierung, Berechtigungen, Abrufkonfiguration und Überwachung zuständig sind. Ohne einen geschlossenen Kreislauf zwischen fehlgeschlagenen Antworten und Quellaktualisierungen nimmt die Abrufqualität normalerweise mit der Zeit ab.
Funktioniert RAG mit privaten oder autorisierten Daten?
Das ist möglich, aber Käufer sollten den Umgang mit Berechtigungen sorgfältig prüfen. Das System muss berücksichtigen, wer die einzelnen Quellen abrufen darf, ob eingeschränkte Inhalte in Antworten angezeigt werden dürfen, wie Zugriffsänderungen synchronisiert werden und wie der Abruf protokolliert wird. Fehler bei der Berechtigung können dazu führen, dass ein nützliches Wissenssystem zu einem Risiko für die Offenlegung von Daten wird.
Was ist der Unterschied zwischen RAG und Agent-RAG?
Basic RAG ruft einmal ab und generiert. Agentic RAG ermöglicht es dem Agenten, mehrere Abrufschritte durchzuführen, Tools aufzurufen und Suchen basierend auf Zwischenergebnissen zu verfeinern. Agentic RAG eignet sich besser für komplexe, mehrstufige Fragen, die die Kombination von Informationen aus mehreren Quellen oder APIs erfordern. Für einfache Fragen im FAQ-Stil reicht oft ein einfaches RAG aus.
Warum ist Chunking für die RAG-Qualität wichtig?
Chunking bestimmt, wie Dokumente in abrufbare Einheiten aufgeteilt werden. Schlechtes Chunking kann dazu führen, dass relevante Informationen halbiert werden, der Kontext um wichtige Passagen verloren geht oder irrelevante Fragmente abgerufen werden. Kleinere Blöcke verbessern die Präzision, verlieren jedoch den umgebenden Kontext. Größere Abschnitte bewahren den Kontext, verwässern jedoch die Relevanz. Beim semantischen Chunking wird versucht, die Aufteilung anhand von Bedeutungsgrenzen und nicht an willkürlichen Grenzen vorzunehmen, was bei komplexen Dokumenten oft zu besseren Ergebnissen führt.
Sollte ich Anbieter nach der Hybridsuche fragen?
Ja. Die Hybridsuche kombiniert Schlüsselwort- und Vektorabfrage, wodurch sowohl exakte Übereinstimmungen (wie Fehlercodes und Produktnamen) als auch konzeptionelle Übereinstimmungen (umschriebene Fragen) erfasst werden. Einem System, das nur eine Vektorsuche durchführt, fehlen möglicherweise genaue Bezeichner. Ein System, das nur eine Stichwortsuche durchführt, kann bei Fragen in natürlicher Sprache scheitern. Fragen Sie, ob die Plattform beides unterstützt, ob ein Reranking enthalten ist und wie Ergebnisse zusammengeführt werden.
Benötige ich multimodales RAG, wenn meine Dokumente hauptsächlich aus Text bestehen?
Es kommt auf Ihren Inhalt an. Wenn Ihr Help Center Screenshots, Produktdiagramme, Preistabellen oder PDFs mit eingebetteten Bildern enthält, werden in einem reinen Text-RAG-System Informationen übersehen, die in diesen Formaten gesperrt sind. Bei Produkten mit visueller Dokumentation, Montageanleitungen oder Fehler-Screenshots kann eine multimodale Recherche unerlässlich sein. Fragen Sie, ob die Plattform Bilder, Tabellen und strukturierte Daten indizieren und abrufen kann, nicht nur Text.
Was sollte ich über das Einbetten von Modellen wissen?
Einbettungsmodelle konvertieren Text für die semantische Suche in Vektordarstellungen. Die Wahl des Modells beeinflusst die Abrufqualität, die Sprachabdeckung und die Domänenspezifität. Fragen Sie, welches Einbettungsmodell die Plattform verwendet, ob sie die von Ihnen benötigten Sprachen unterstützt, ob eine Domänenanpassung verfügbar ist und was passiert, wenn das Modell aktualisiert wird. Der Wechsel des Einbettungsmodells erfordert eine Neuindizierung aller Dokumente.
Ist das Reranking die zusätzliche Latenz wert?
Das Reranking verbessert die Relevanz, indem die ersten Ergebnisse mit einem leistungsfähigeren Modell neu bewertet werden. Bei mehrdeutigen Abfragen oder großen Dokumentensätzen führt eine Neuordnung oft zu besseren Antworten. Der Kompromiss besteht in der zusätzlichen Latenz (normalerweise 50–500 ms pro Abfrage) und den Kosten. Für Echtzeitunterstützung, bei der es auf die Latenz ankommt, testen Sie, ob eine Neubewertung die Antwortqualität ausreichend verbessert, um die Verzögerung zu rechtfertigen. Bei Batch- oder asynchronen Anwendungsfällen lohnt sich in der Regel ein Reranking.