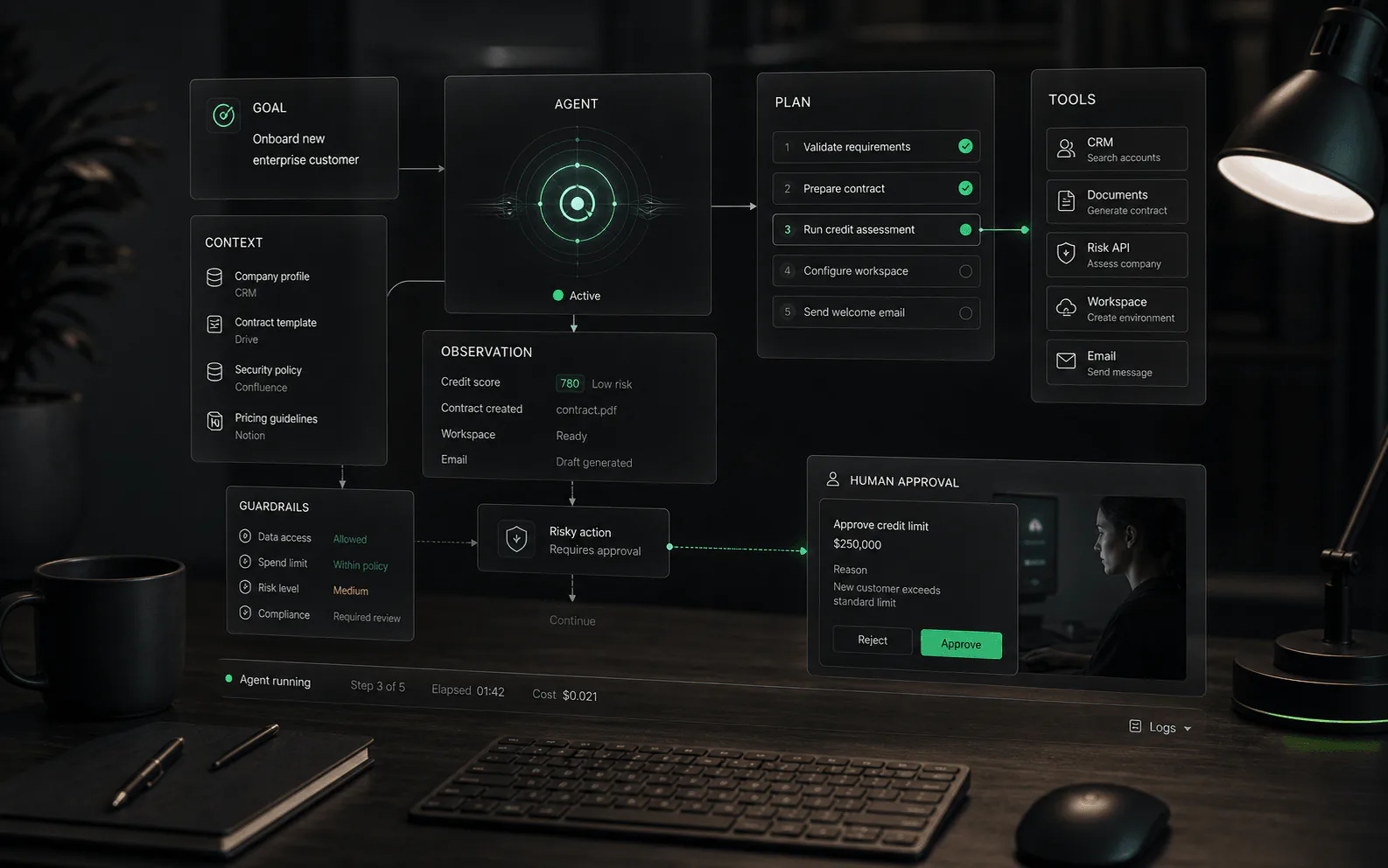
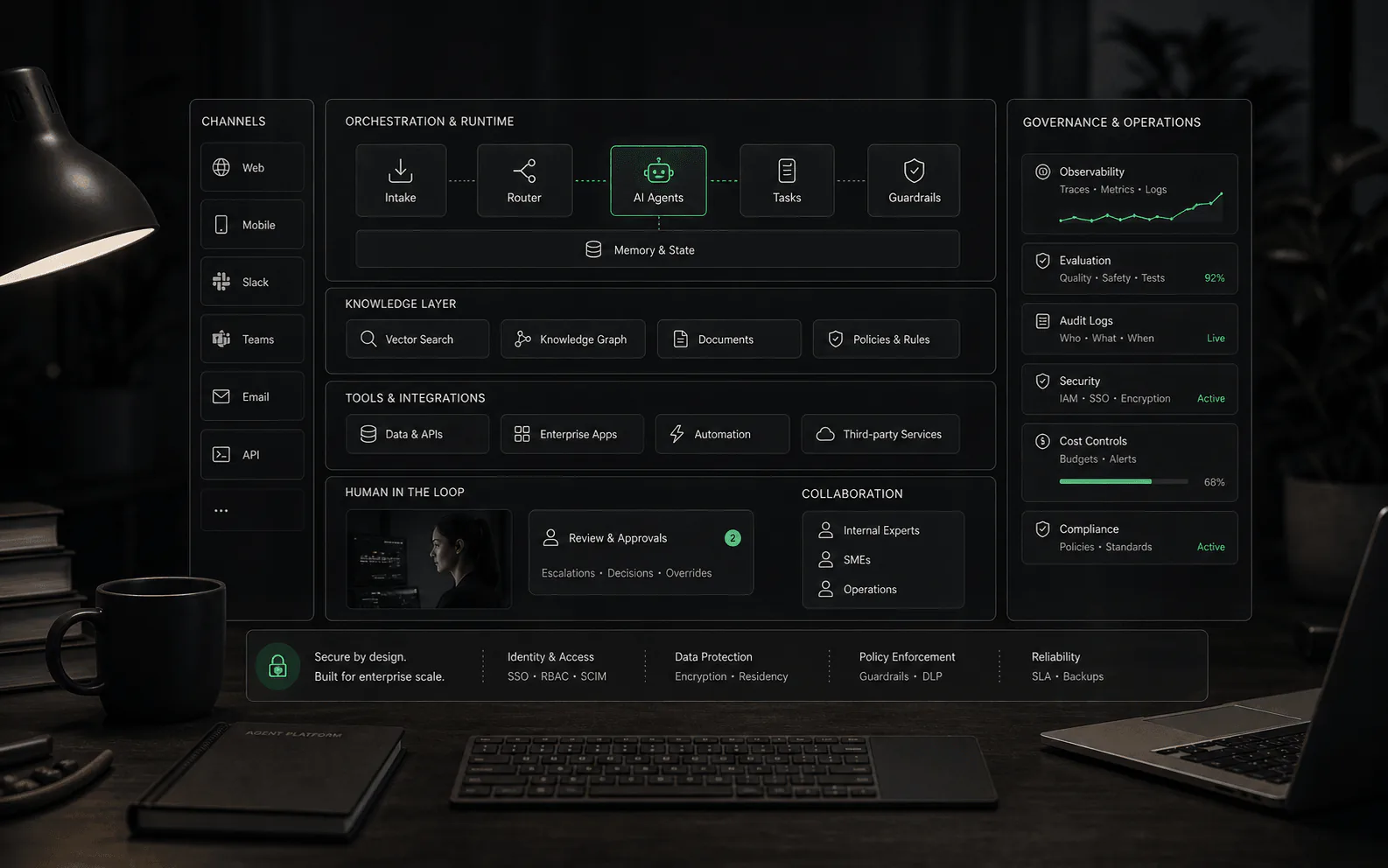
¿Qué hace RAG?
RAG conecta la generación con la recuperación. En lugar de pedirle a un modelo que responda únicamente a partir de su capacitación general, el sistema busca fuentes aprobadas, selecciona pasajes o registros relevantes y utiliza ese contexto para producir una respuesta. En los productos de agentes de IA, esas fuentes pueden incluir centros de ayuda, documentos internos, manuales de productos, páginas de políticas, registros de CRM, datos de pedidos u otros sistemas comerciales, según lo que admita la plataforma.
Cómo funciona RAG
- Ingesta: las fuentes aprobadas se recopilan de documentos, centros de ayuda, bases de datos, API u otros repositorios.
- Preparar: el contenido se analiza, se limpia, se divide en partes significativas, se etiqueta, se autoriza y se indexa para su recuperación.
- Recuperar: cuando un usuario hace una pregunta, el sistema busca material fuente relevante mediante búsqueda de palabras clave, búsqueda de vectores, búsqueda híbrida, reclasificación u otro enfoque de recuperación.
- Aumento: el contexto seleccionado se ensambla en el mensaje del modelo con instrucciones sobre cómo usarlo.
- Generar: el modelo escribe una respuesta utilizando el contexto recuperado, idealmente con visibilidad de la fuente para los revisores o usuarios cuando sea apropiado.
- Mejorar: las consultas fallidas y las respuestas corregidas se retroalimentan en la higiene del origen, el ajuste de recuperación y los conjuntos de evaluación.
Por qué es importante para los agentes de IA
RAG es una de las principales formas en que un agente de IA se vuelve específico para el negocio. Un agente de soporte que no puede recuperar la política de reembolso actual, la regla de garantía, la página de precios, la limitación del producto o el contexto de la cuenta a menudo producirá respuestas fluidas pero poco confiables. Una buena recuperación no hace que el sistema sea perfecto, pero le da al agente una mejor oportunidad de responder a partir del material en el que la empresa realmente confía.
RAG puede fallar en varias capas
- Fallo de fuente: la respuesta correcta está ausente, obsoleta, duplicada, contradicha o escrita de una manera que el recuperador no puede usar.
- Fallo de indexación: el contenido estaba mal fragmentado, etiquetado incorrectamente, incrustado sin metadatos útiles o no se actualizó después de una actualización.
- Fallo de recuperación: el sistema encuentra el pasaje incorrecto, omite un sinónimo, clasifica el contenido antiguo por encima del contenido actual o recupera material que el usuario no debería ver.
- Fallo de conexión a tierra: el modelo recibe el contexto correcto pero lo ignora, lo extiende demasiado o lo malinterpreta.
- Experimente el fracaso: la respuesta parece segura, pero no proporciona a los revisores ningún rastro de la fuente, señal de incertidumbre ni ruta de escalada.
La calidad depende de algo más que la carga de archivos
- Calidad de la fuente: los documentos obsoletos, duplicados, contradictorios o mal estructurados dan lugar a respuestas deficientes.
- Fragmentación e indexación: el sistema tiene que dividir y almacenar el conocimiento de manera que preserve el significado.
- Calidad de recuperación: el agente debe encontrar el contexto adecuado para preguntas confusas del mundo real, no solo coincidencias exactas de palabras clave.
- Manejo de permisos: el contenido privado o con roles restringidos no debe aparecer en las respuestas del usuario equivocado.
- Comportamiento alternativo: el sistema debe saber cuándo faltan fuentes, cuándo son débiles o entran en conflicto en lugar de inventar certezas.
- Revisar el flujo de trabajo: los equipos necesitan una forma de identificar respuestas incorrectas y corregir el material fuente o las reglas de recuperación.
Qué deberían probar los compradores
- Haga preguntas cuya respuesta exista en una fuente aprobada y en ningún otro lugar.
- Haga preguntas donde dos documentos entren en conflicto y vea si el agente nota incertidumbre.
- Pregunte acerca de una política desactualizada y verifique si gana la fuente más reciente.
- Haga preguntas relacionadas con permisos y confirme que el contenido restringido permanece restringido.
- Haga preguntas sin una fuente confiable y verifique si el agente dice que no sabe o se intensifica.
- Revise si las citas o fragmentos de fuentes están disponibles para los humanos para el control de calidad.
Conjunto de datos de evaluación para demostraciones de RAG
Una demostración seria de RAG debería utilizar un conjunto de pruebas pequeño pero realista antes de la adquisición. Incluya preguntas con una fuente clara, preguntas que requieran dos fuentes, preguntas con trampas obsoletas, preguntas con contenido restringido, preguntas que no deberían generar respuesta y preguntas que utilicen el lenguaje del cliente en lugar de terminología interna. El objetivo es separar la fluidez en las respuestas de la calidad de la recuperación.
Ejemplos concretos y no ejemplos
- Ejemplo: un agente de soporte recupera la política de garantía actual, cita la fuente relevante internamente y responde solo dentro de los límites de esa política.
- Ejemplo: un agente de operaciones internas busca en una biblioteca de procedimientos antes de redactar el siguiente paso para una solicitud de empleado.
- Ejemplo: un agente de comercio electrónico recupera el contexto específico del pedido y la documentación del producto antes de explicar qué información necesita un ser humano para revisar una devolución.
- No ejemplo: un modelo responde desde la memoria general sin verificar fuentes comerciales aprobadas.
- No es un ejemplo: un proveedor carga documentos una vez pero no proporciona ningún proceso de actualización, controles de permisos, visibilidad de la fuente ni informes de fallas.
Entrenamiento RAG versus modelo
RAG no es lo mismo que entrenar un modelo. La capacitación cambia el comportamiento del modelo a través del aprendizaje adicional. RAG recupera información externa en el momento de la respuesta. Para los compradores, esa distinción es importante porque RAG a menudo puede reflejar contenido comercial actualizado más rápido, pero también depende en gran medida de la actualización de la fuente, la indexación, los permisos y la calidad de recuperación.
RAG versus contexto largo
Los modelos de contexto largo pueden aceptar grandes cantidades de texto en un mensaje, pero eso no es automáticamente RAG. RAG implica recuperación selectiva: el sistema elige material relevante de un conjunto de fuentes más grande antes de la generación. Volcar un archivo grande en contexto puede ser útil para tareas específicas, pero no resuelve por sí solo la actualización del código fuente, los permisos, la clasificación, la resolución de conflictos ni las operaciones de conocimiento recurrentes.
Banderas rojas
Sea escéptico cuando un proveedor trate la carga de un PDF como prueba de una base de conocimientos confiable. También tenga cuidado con la falta de visibilidad de la fuente, sin controles de actualización, sin modelo de permiso, sin forma de manejar documentos conflictivos, sin informes sobre preguntas sin respuesta y sin proceso para mejorar la recuperación deficiente después del lanzamiento.
Métricas a monitorear
La calidad de RAG debe medirse más allá de la fluidez en las respuestas. Las señales útiles incluyen la tasa de aciertos en la recuperación de preguntas con respuestas conocidas, la actualidad de las fuentes, la tasa de consultas no resueltas, la precisión de las citas, los errores de permisos, los incidentes con fuentes conflictivas, la tasa de corrección de respuestas y la cantidad de preguntas fallidas que se convierten en mejoras del conocimiento. Estas medidas ayudan a separar el material fuente débil de la recuperación y la generación débiles.
Operaciones de conocimiento
RAG crea un problema continuo de operaciones de conocimiento. Alguien debe decidir qué fuentes se aprueban, eliminar duplicados, archivar material obsoleto, resolver conflictos de políticas y revisar las preguntas que el agente no pudo responder. Los compradores deben preguntarse si las operaciones de soporte, las operaciones de productos, la documentación o la TI serán dueñas de ese bucle. Sin un propietario designado, la calidad de la recuperación generalmente se degrada a medida que cambian los productos, las políticas y el idioma del cliente.
Propiedad después del lanzamiento
El propietario de la calidad de RAG debe tener autoridad para cambiar el material fuente, no solo leer análisis. Si los equipos de soporte encuentran errores repetidos en la recuperación pero los propietarios de la documentación no pueden actualizar los artículos rápidamente, el agente seguirá fallando de la misma manera. Un bucle operativo útil conecta preguntas fallidas, correcciones de fuentes, reindexación, pruebas de regresión y aprobación del revisor antes de que el conocimiento actualizado entre en producción.
RAG agente
Agentic RAG amplía el RAG tradicional al permitir que el agente de IA realice múltiples pasos de recuperación, llame a herramientas y refine su búsqueda en función de resultados intermedios. En lugar de un único paso de recuperación y luego generación, el agente puede decidir buscar nuevamente, probar diferentes consultas, llamar a API o combinar información de múltiples fuentes mediante un razonamiento iterativo. Esto es importante para las plataformas de agentes de IA porque las preguntas comerciales complejas a menudo requieren una investigación de varios pasos: un agente de soporte puede primero recuperar la política de reembolso, luego verificar el estado del pedido del cliente a través de API y luego recuperar los términos de garantía específicos del producto antes de responder.
- Recuperación iterativa: el agente puede emitir múltiples consultas, refinar en función de lo que encuentra y decidir cuándo dejar de buscar.
- Aumento de herramientas: el agente combina la recuperación de documentos con búsquedas en bases de datos, llamadas API y cálculos, no solo texto estático.
- Autocorrección: cuando la recuperación inicial arroja malos resultados, el agente puede reformular, ampliar o girar en lugar de alucinar.
- Memoria entre turnos: el RAG agente a menudo mantiene el contexto de turnos anteriores en una conversación, lo que permite hacer preguntas de seguimiento sin tener que volver a recuperar todo.
- Planificar y ejecutar: algunos sistemas RAG agentes planifican una estrategia de recuperación antes de ejecutar, lo que reduce el esfuerzo desperdiciado en rutas irrelevantes.
Para los compradores que evalúan plataformas de agentes de IA, las capacidades RAG de agentes se vuelven importantes cuando el caso de uso implica investigaciones complejas de varios pasos en lugar de simples respuestas al estilo de las preguntas frecuentes. Pregunte a los proveedores si la recuperación es de un solo paso o iterativa, si el agente puede llamar a las herramientas en mitad de la recuperación y cómo maneja el sistema los casos en los que la primera búsqueda no arroja nada útil. Un sistema RAG de un solo paso tendrá problemas con preguntas como "¿por qué se cobró a mi cuenta dos veces este mes?" donde la respuesta requiere recuperar la política de facturación, verificar el historial de transacciones a través de API y comparar fechas.
Búsqueda híbrida
La búsqueda híbrida combina múltiples métodos de recuperación (normalmente palabras clave (BM25), similitud de vectores y, a veces, reclasificación semántica) para mejorar la calidad de la recuperación. La búsqueda pura de palabras clave omite sinónimos y coincidencias conceptuales. La búsqueda vectorial pura puede perder coincidencias exactas o verse alterada por la incorporación de ruido. La búsqueda híbrida reduce ambos modos de falla al clasificar los resultados de múltiples métodos y fusionarlos de manera inteligente.
- Búsqueda de palabras clave (BM25): encuentra términos y frases exactos. Fuerte para nombres de productos, SKU, códigos de error e identificadores específicos. Débil para preguntas conceptuales o intención parafraseada.
- Búsqueda de vectores (semántica): busca significado comparando vectores integrados. Excelente para preguntas parafraseadas, coincidencias conceptuales y recuperación en varios idiomas. Débil para identificadores exactos y a veces confundido por conceptos que suenan similares.
- Reclasificación: un modelo de segunda etapa califica los resultados iniciales con más cuidado, a menudo utilizando un codificador cruzado que evalúa conjuntamente la consulta y el documento. La reclasificación mejora la precisión a costa de la latencia.
- Fusión: los resultados de la búsqueda de palabras clave y vectores se combinan mediante una fusión de clasificación recíproca o una puntuación aprendida, y luego, opcionalmente, se reclasifican.
Para los compradores de agentes de IA, a menudo vale la pena preguntar sobre la búsqueda híbrida. Un proveedor que se basa únicamente en la búsqueda vectorial puede perder coincidencias exactas que un cliente esperaría encontrar. Un proveedor que se basa únicamente en la búsqueda de palabras clave puede fallar en consultas en lenguaje natural que utilizan una redacción diferente a la de la documentación. Haga preguntas de demostración que combinen necesidades conceptuales y de términos exactos: "¿Cuál es la diferencia entre los niveles de precios Pro y Enterprise?" (requiere buscar páginas de precios y comparar) o "¿Cómo soluciono el error 503?" (requiere hacer coincidir el código de error mientras se comprende el contexto).
Recuperación multimodal
La recuperación multimodal extiende RAG más allá del texto para incluir imágenes, tablas, vídeos, audio y datos estructurados. El conocimiento empresarial suele ser multimodal: los manuales de productos contienen diagramas y tablas, los centros de ayuda incluyen capturas de pantalla, los tickets de soporte tienen fotografías adjuntas y los documentos de políticas incorporan gráficos. Un sistema RAG de solo texto perderá información bloqueada en formatos que no son de texto, lo que generará respuestas incompletas o incorrectas.
- Imágenes: recuperación de diagramas, capturas de pantalla, fotografías de productos y capturas de pantalla de errores. Requiere incrustaciones con capacidad de visión o canalizaciones de OCR.
- Tablas: extracción de datos estructurados de archivos PDF, hojas de cálculo y tablas HTML. Las tablas suelen contener precios, especificaciones y datos comparativos que la fragmentación del texto destruye.
- Vídeo y audio: indexación de marcas de tiempo, transcripciones y fotogramas visuales de vídeos de formación, seminarios web y llamadas de soporte grabadas.
- Datos estructurados: consulta de bases de datos, API y gráficos de conocimiento junto con documentos no estructurados. Permite respuestas que combinan explicación narrativa con datos en vivo.
Para los compradores, el soporte multimodal es importante cuando la base de conocimientos incluye activos no textuales. Pregunte si la plataforma puede indexar y recuperar archivos PDF con imágenes incrustadas, si las tablas se conservan como datos estructurados en lugar de dividirse en fragmentos de texto incoherentes y si se admiten consultas basadas en imágenes (como "muéstreme el diagrama de cableado del modelo X"). Una plataforma que solo indexa texto devolverá respuestas incompletas para productos con documentación visual, instrucciones de ensamblaje con diagramas o tickets de soporte con capturas de pantalla de errores.
Estrategias de fragmentación
La fragmentación es la forma en que los documentos se dividen en unidades recuperables antes de indexarlos. El tamaño de los fragmentos y la superposición afectan drásticamente la calidad de la recuperación. Los fragmentos pequeños conservan detalles específicos pero pierden contexto. Grandes porciones preservan el contexto pero diluyen la relevancia y consumen el presupuesto de la ventana de contexto. La superposición ayuda a garantizar que los pasajes relevantes no queden cortados en los límites. La fragmentación semántica intenta dividir los límites de los conceptos en lugar de los límites arbitrarios de los caracteres o las oraciones.
- Tamaño del fragmento: normalmente entre 200 y 1000 tokens. Los fragmentos más pequeños mejoran la precisión de preguntas específicas, pero pueden pasar por alto el contexto circundante. Los fragmentos más grandes proporcionan contexto pero pueden recuperar material irrelevante.
- Superposición: una superposición del 10 al 20 % entre fragmentos ayuda a garantizar que los pasajes relevantes abarquen los límites de los fragmentos. Si no se superponen, se corre el riesgo de reducir la información clave a la mitad.
- Fragmentación semántica: utiliza incrustaciones o estructuras de oraciones (encabezados, párrafos, secciones) para dividir en límites de significado en lugar de tamaños fijos. Conserva ideas coherentes pero requiere más procesamiento.
- Fragmentación padre-hijo: recupera fragmentos pequeños para mayor relevancia pero carga fragmentos principales más grandes para contexto. Equilibra precisión y contexto.
- Fragmentación de tablas y códigos: requiere un manejo especial. Las tablas a menudo deben dividirse en unidades o filas conservando los encabezados. Los fragmentos de código necesitan contexto de función.
La calidad de la fragmentación a menudo explica por qué los mismos documentos producen respuestas diferentes en todas las plataformas. Para los compradores, pregunte cómo maneja la plataforma la fragmentación, si hay controles para el tamaño y la superposición de la fragmentación, si las tablas y el código se manejan de manera especial y si la fragmentación se puede ajustar según el tipo de documento. Un proveedor que trata todos los documentos por igual tendrá dificultades con tipos de contenido mixtos: un manual de políticas en PDF de 50 páginas necesita una fragmentación diferente a la de un conjunto de entradas breves de preguntas frecuentes.
Consideraciones sobre el modelo de incrustación
Los modelos de incrustación convierten texto en representaciones vectoriales para búsqueda semántica. La elección del modelo de incorporación afecta la calidad de la recuperación, la cobertura del idioma, la especificidad del dominio y el costo. Los modelos más nuevos a menudo superan a los más antiguos, pero cambiar de modelo integrado requiere volver a indexar todo el corpus. Los compradores deben comprender qué modelo de integración utiliza una plataforma, con qué frecuencia se actualiza y qué sucede cuando se actualizan los modelos.
- Calidad del modelo: los modelos integrados difieren en su capacidad para capturar similitudes semánticas, manejar diferentes lenguajes y representar terminología específica de dominio. Un modelo entrenado en texto web general puede tener dificultades con la documentación médica, legal o técnica.
- Tamaño y velocidad del modelo: los modelos más grandes a menudo producen mejores incrustaciones, pero su ejecución cuesta más. Para la recuperación de grandes volúmenes, la compensación entre calidad y latencia es importante.
- Adaptación del dominio: algunas plataformas permiten realizar ajustes finos en los datos del dominio. Esto puede mejorar la recuperación de vocabulario especializado, pero añade complejidad y coste de mantenimiento.
- Soporte multilingüe: los modelos de integración varían en la cobertura de idiomas. Un modelo entrenado principalmente en inglés puede funcionar mal en otros idiomas, lo que afecta las implementaciones globales.
- Actualizaciones y reindexación de modelos: cuando se actualizan o reemplazan modelos integrados, se deben volver a incrustar todos los documentos. Pregunte si las actualizaciones son automáticas, si provocan tiempo de inactividad y si se supervisan las regresiones de la calidad de recuperación.
Para los compradores que evalúan plataformas, la elección del modelo de integración suele ser invisible pero impactante. Pregunte qué modelo de integración se utiliza, si admite los idiomas necesarios, si hay adaptación de dominio disponible y qué sucede cuando se actualiza el modelo. Una plataforma que lo encierra en un modelo de integración obsoleto verá degradarse la calidad de recuperación en relación con los competidores que actualizan.
Reclasificación de modelos
La reclasificación es un paso de recuperación de segunda etapa que vuelve a calificar los resultados iniciales utilizando un modelo más potente (generalmente codificador cruzado). Después de que la recuperación inicial mediante búsqueda de palabras clave o vectores arroja quizás entre 50 y 100 pasajes candidatos, un reclasificador evalúa conjuntamente cada par de consulta y documento para producir una puntuación de relevancia más precisa. La reclasificación mejora la precisión a costa de una mayor latencia.
- Codificadores cruzados: el modelo de reclasificación ve la consulta y el documento juntos, lo que le permite capturar interacciones que los modelos de incorporación de codificadores bidireccionales pasan por alto. Esto produce mejores puntuaciones de relevancia pero es más lento.
- API de reclasificación: algunas plataformas utilizan API de reclasificación externas (Cohere, Jina, Voyage, etc.), mientras que otras alojan modelos de reclasificación internamente. La reclasificación alojada externamente puede agregar problemas de latencia y transferencia de datos.
- Selección top-k: la reclasificación generalmente se aplica a los 20-100 mejores resultados iniciales. Después de la reclasificación, solo los primeros pasan al modelo de generación.
- Compensación entre calidad y latencia: la reclasificación mejora la relevancia de las respuestas, pero agrega una latencia de 50 a 500 ms por consulta. Para obtener soporte en tiempo real, se debe evaluar esta compensación.
- Costo: la reclasificación es más costosa desde el punto de vista computacional que la recuperación inicial. Para sistemas de gran volumen, el costo de reclasificar cada consulta aumenta.
Para los compradores, la reclasificación es una capacidad sobre la que preguntar específicamente. Una plataforma que solo realiza la recuperación inicial puede arrojar resultados menos relevantes para consultas ambiguas. Una plataforma con reclasificación puede producir mejores respuestas pero con mayor latencia y costo. Pregunte si se incluye la reclasificación, si se aplica de forma predeterminada, si existen controles sobre cuándo cambiar la clasificación y cómo mide el proveedor la mejora de la calidad. Una demostración que se ve muy bien en preguntas cuidadosamente seleccionadas puede no mostrar el valor de cambiar la clasificación en consultas complicadas del mundo real.
Fuentes para verificar
Utilice estas referencias para comprender el término y las afirmaciones de los proveedores de pruebas de presión. Los detalles específicos del producto aún deben verificarse con los materiales actuales del proveedor.
Preguntas frecuentes
Preguntas comunes
¿RAG es lo mismo que entrenar un modelo de IA?
No. La capacitación cambia el comportamiento del modelo. RAG recupera información externa en el momento de la respuesta, por lo que la calidad depende en gran medida de las fuentes conectadas, la lógica de recuperación y la actualidad del contenido indexado.
¿RAG previene las alucinaciones?
No. RAG puede reducir las respuestas no respaldadas cuando la recuperación y la calidad de la fuente son sólidas, pero no garantiza la precisión. Los compradores aún necesitan un comportamiento alternativo, revisión de fuentes, pruebas y supervisión humana para flujos de trabajo riesgosos.
¿RAG es lo mismo que búsqueda semántica?
No. La búsqueda semántica ayuda a recuperar información relevante, a menudo haciendo coincidir el significado en lugar de palabras clave exactas. RAG utiliza la recuperación como un paso en un patrón más amplio: recuperar el contexto relevante, pasarlo a un modelo generativo y producir una respuesta. Un sistema puede realizar búsqueda semántica sin generación y puede generar texto sin realizar una recuperación confiable.
¿Subir documentos a un chatbot es lo mismo que RAG?
No por sí solo. Los documentos cargados se pueden utilizar en un sistema RAG si el chatbot recupera pasajes relevantes de esos documentos en el momento de la respuesta y los utiliza como contexto para la generación. Pero un botón para cargar archivos no prueba cómo funciona la recuperación, si se seleccionan los pasajes correctos, si las fuentes son recientes o si la respuesta permanece basada en el material recuperado. Para los compradores, la prueba consiste en inspeccionar el paso de recuperación, la visibilidad de la fuente y el comportamiento de falla.
¿En qué se diferencia RAG del ajuste fino?
El ajuste fino cambia el comportamiento del modelo entrenando con ejemplos o datos adicionales. RAG recupera información externa en el momento de la respuesta y la utiliza como contexto para la respuesta. RAG suele ser más adecuado para cambiar el conocimiento empresarial porque las fuentes se pueden actualizar sin volver a capacitarse, pero la calidad aún depende de la recuperación, los permisos y la higiene de las fuentes.
¿Qué deberían probar los compradores en una demostración de RAG?
Utilice preguntas con una fuente clara, preguntas que requieran múltiples fuentes, trampas de políticas obsoletas, contenido sensible a permisos, sinónimos que los clientes realmente usan y preguntas cuya respuesta correcta deba ser desconocida. Solicite ver las fuentes recuperadas, no solo la respuesta final, para poder saber si la respuesta fue fundamentada o simplemente fluida.
¿Qué causa que los sistemas RAG den respuestas incorrectas?
Las respuestas incorrectas pueden provenir de fuentes obsoletas, documentos conflictivos, fragmentación deficiente, recuperación débil, metadatos faltantes, errores de permisos, límites de la ventana de contexto o un modelo que ignora el material recuperado. La depuración de RAG requiere separar los problemas de origen, los problemas de recuperación, los problemas de conexión a tierra y los problemas de generación en lugar de tratar cada falla como un problema inmediato.
¿Quién debería poseer la calidad RAG después del lanzamiento?
La calidad RAG necesita un propietario operativo con autoridad para mejorar el material original. Las operaciones de soporte, las operaciones de productos, la documentación o la gestión del conocimiento pueden ser dueñas de la calidad del contenido, mientras que los equipos técnicos son dueños de la indexación, los permisos, la configuración de recuperación y el monitoreo. Sin un circuito cerrado entre las respuestas fallidas y las actualizaciones de las fuentes, la calidad de la recuperación suele degradarse con el tiempo.
¿RAG trabaja con datos privados o autorizados?
Puede, pero los compradores deben verificar cuidadosamente el manejo del permiso. El sistema debe respetar quién tiene permiso para recuperar cada fuente, si puede aparecer contenido restringido en las respuestas, cómo se sincronizan los cambios de acceso y cómo se registra la recuperación. Los errores de permisos pueden convertir un sistema de conocimiento útil en un riesgo de exposición de datos.
¿Cuál es la diferencia entre RAG y RAG agente?
RAG básico se recupera una vez y genera. Agentic RAG permite al agente realizar múltiples pasos de recuperación, llamar a herramientas y refinar las búsquedas en función de resultados intermedios. Agentic RAG es mejor para preguntas complejas de varios pasos que requieren combinar información de múltiples fuentes o API. Para preguntas sencillas tipo preguntas frecuentes, el RAG básico suele ser suficiente.
¿Por qué la fragmentación es importante para la calidad de RAG?
La fragmentación determina cómo se dividen los documentos en unidades recuperables. Una fragmentación deficiente puede dividir la información relevante a la mitad, perder el contexto en torno a pasajes clave o recuperar fragmentos irrelevantes. Los fragmentos más pequeños mejoran la precisión pero pierden el contexto circundante. Los fragmentos más grandes preservan el contexto pero diluyen la relevancia. La fragmentación semántica intenta dividir en límites de significado en lugar de límites arbitrarios, lo que a menudo produce mejores resultados para documentos complejos.
¿Debería preguntar a los proveedores sobre la búsqueda híbrida?
Sí. La búsqueda híbrida combina la recuperación de palabras clave y vectores, que detecta coincidencias exactas (como códigos de error y nombres de productos) y coincidencias conceptuales (preguntas parafraseadas). Un sistema que sólo realiza búsquedas vectoriales puede perder identificadores exactos. Un sistema que sólo realiza búsquedas por palabras clave puede fallar en preguntas en lenguaje natural. Pregunte si la plataforma admite ambos, si se incluye la reclasificación y cómo se combinan los resultados.
¿Necesito RAG multimodal si mis documentos son en su mayoría de texto?
Depende de tu contenido. Si su centro de ayuda incluye capturas de pantalla, diagramas de productos, tablas de precios o archivos PDF con imágenes incrustadas, un sistema RAG de solo texto perderá información bloqueada en esos formatos. Para productos con documentación visual, instrucciones de ensamblaje o capturas de pantalla de errores, la recuperación multimodal puede ser esencial. Pregunte si la plataforma puede indexar y recuperar imágenes, tablas y datos estructurados, no solo texto.
¿Qué debo saber sobre la incrustación de modelos?
Los modelos de incrustación convierten texto en representaciones vectoriales para búsqueda semántica. La elección del modelo afecta la calidad de la recuperación, la cobertura del idioma y la especificidad del dominio. Pregunte qué modelo de integración utiliza la plataforma, si admite los idiomas que necesita, si hay adaptación de dominio disponible y qué sucede cuando se actualiza el modelo. Cambiar los modelos de incrustación requiere volver a indexar todos los documentos.
¿Vale la pena la latencia adicional para cambiar la clasificación?
La reclasificación mejora la relevancia al volver a calificar los resultados iniciales con un modelo más potente. Para consultas ambiguas o conjuntos de documentos grandes, la reclasificación suele producir mejores respuestas. La desventaja es la latencia adicional (normalmente entre 50 y 500 ms por consulta) y el costo. Para obtener soporte en tiempo real donde la latencia es importante, pruebe si la reclasificación mejora la calidad de la respuesta lo suficiente como para justificar el retraso. Para casos de uso por lotes o asincrónicos, normalmente vale la pena reclasificar.