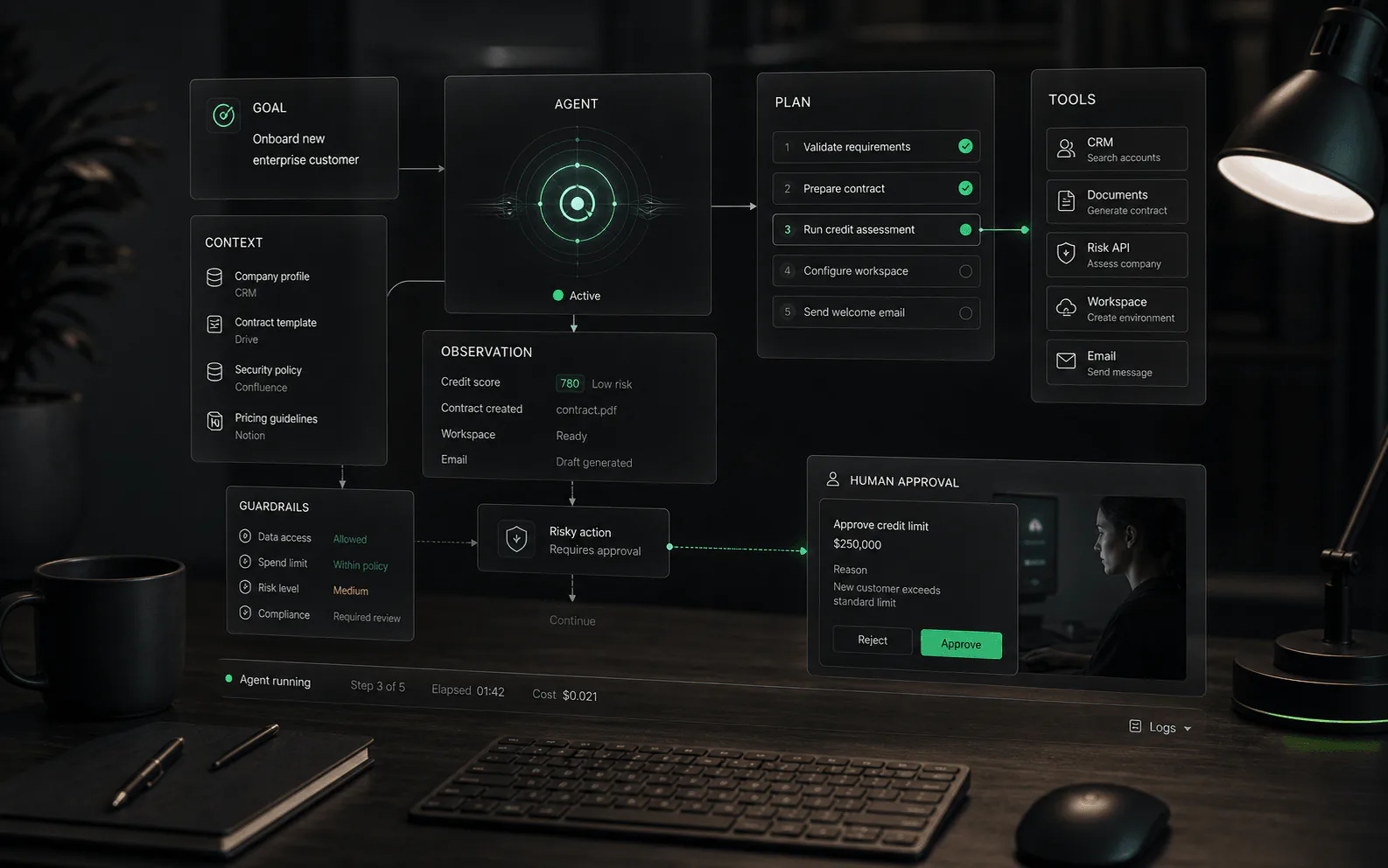
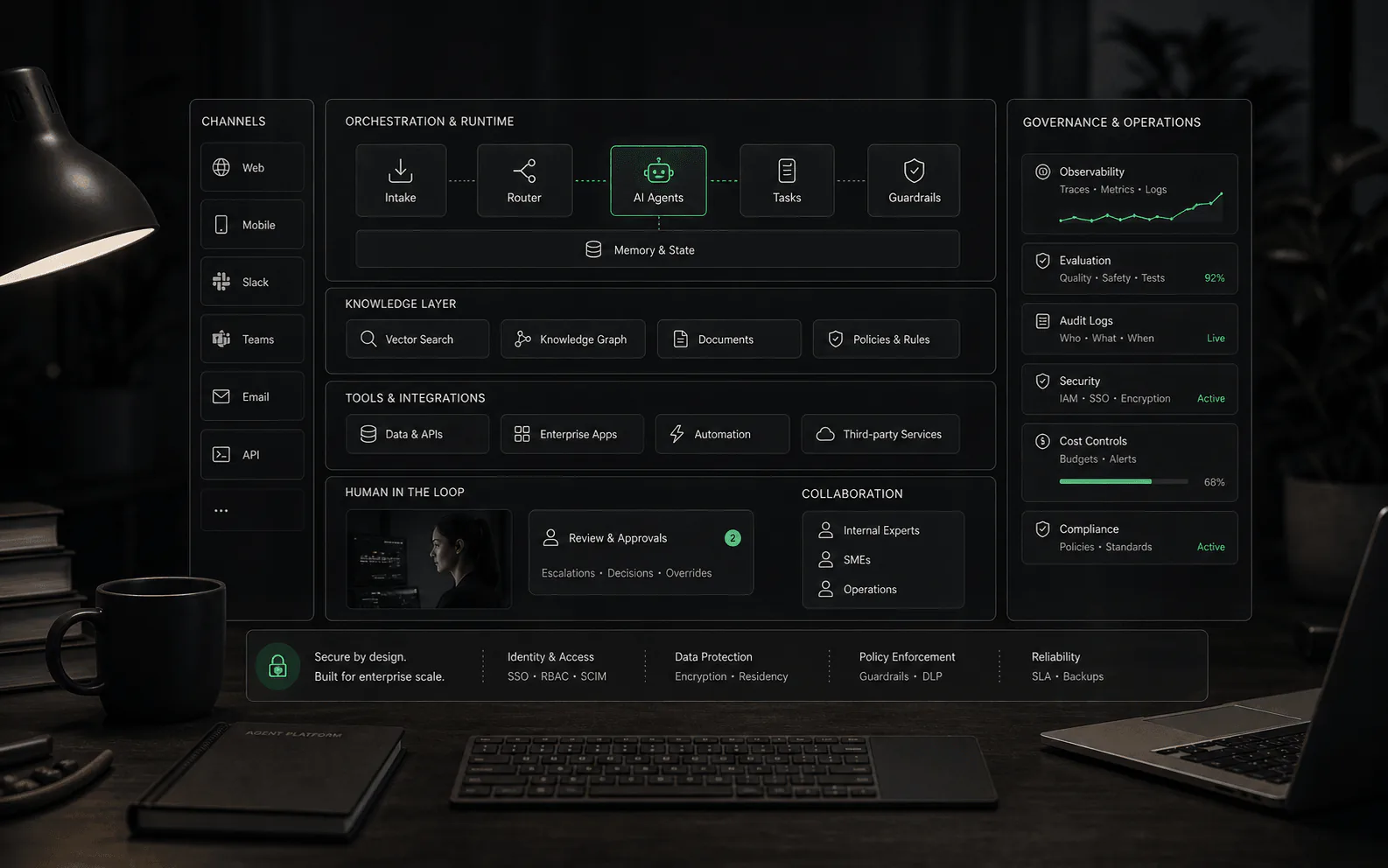
What RAG does
RAG connects generation to retrieval. Instead of asking a model to answer from its general training alone, the system searches approved sources, selects relevant passages or records, and uses that context to produce an answer. In AI agent products, those sources might include help centers, internal docs, product manuals, policy pages, CRM records, order data, or other business systems, depending on what the platform supports.
How RAG works
- Ingest: approved sources are collected from documents, help centers, databases, APIs, or other repositories.
- Prepare: content is parsed, cleaned, split into meaningful chunks, tagged, permissioned, and indexed for retrieval.
- Retrieve: when a user asks a question, the system searches for relevant source material using keyword search, vector search, hybrid search, reranking, or another retrieval approach.
- Augment: the selected context is assembled into the model prompt with instructions about how to use it.
- Generate: the model writes an answer using the retrieved context, ideally with source visibility for reviewers or users when appropriate.
- Improve: failed queries and corrected answers feed back into source hygiene, retrieval tuning, and evaluation sets.
Why it matters for AI agents
RAG is one of the main ways an AI agent becomes business-specific. A support agent that cannot retrieve the current refund policy, warranty rule, pricing page, product limitation, or account context will often produce fluent but unreliable answers. Good retrieval does not make the system perfect, but it gives the agent a better chance of answering from the material the business actually trusts.
RAG can fail at several layers
- Source failure: the correct answer is absent, stale, duplicated, contradicted, or written in a way the retriever cannot use.
- Indexing failure: the content was chunked poorly, tagged incorrectly, embedded without useful metadata, or not refreshed after an update.
- Retrieval failure: the system finds the wrong passage, misses a synonym, ranks old content above current content, or retrieves material the user should not see.
- Grounding failure: the model receives the right context but ignores, overextends, or misreads it.
- Experience failure: the answer sounds confident but gives reviewers no source trail, uncertainty signal, or escalation path.
The quality depends on more than file upload
- Source quality: outdated, duplicated, contradictory, or poorly structured documents lead to poor answers.
- Chunking and indexing: the system has to split and store knowledge in a way that preserves meaning.
- Retrieval quality: the agent must find the right context for messy real-world questions, not just exact keyword matches.
- Permission handling: private or role-restricted content should not appear in answers for the wrong user.
- Fallback behavior: the system should know when sources are missing, weak, or conflicting instead of inventing certainty.
- Review workflow: teams need a way to identify bad answers and fix the source material or retrieval rules.
What buyers should test
- Ask questions where the answer exists in one approved source and nowhere else.
- Ask questions where two documents conflict and see whether the agent notices uncertainty.
- Ask about an outdated policy and verify whether the latest source wins.
- Ask permission-sensitive questions and confirm restricted content stays restricted.
- Ask questions with no reliable source and check whether the agent says it does not know or escalates.
- Review whether citations or source snippets are available to humans for QA.
Evaluation dataset for RAG demos
A serious RAG demo should use a small but realistic test set before procurement. Include questions with one clear source, questions that require two sources, questions with outdated traps, questions with restricted content, questions that should produce no answer, and questions using customer language rather than internal terminology. The goal is to separate answer fluency from retrieval quality.
Concrete examples and non-examples
- Example: a support agent retrieves the current warranty policy, cites the relevant source internally, and answers only within that policy's boundary.
- Example: an internal operations agent searches a procedure library before drafting the next step for an employee request.
- Example: an ecommerce agent retrieves order-specific context and product documentation before explaining what information a human needs to review a return.
- Non-example: a model answers from general memory without checking approved business sources.
- Non-example: a vendor uploads documents once but provides no refresh process, permission controls, source visibility, or failure reporting.
RAG versus model training
RAG is not the same as training a model. Training changes model behavior through additional learning. RAG retrieves external information at response time. For buyers, that distinction matters because RAG can often reflect updated business content faster, but it also depends heavily on source freshness, indexing, permissions, and retrieval quality.
RAG versus long context
Long-context models can accept large amounts of text in a prompt, but that is not automatically RAG. RAG implies selective retrieval: the system chooses relevant material from a larger source set before generation. Dumping a large file into context can be useful for narrow tasks, but it does not solve source freshness, permissions, ranking, conflict resolution, or recurring knowledge operations by itself.
Red flags
Be skeptical when a vendor treats upload a PDF as proof of reliable knowledge grounding. Also watch for no source visibility, no refresh controls, no permission model, no way to handle conflicting documents, no reporting on unanswered questions, and no process for improving poor retrieval after launch.
Metrics to monitor
RAG quality should be measured beyond answer fluency. Useful signals include retrieval hit rate on known-answer questions, source freshness, unresolved query rate, citation accuracy, permission failures, conflicting-source incidents, answer correction rate, and the number of failed questions that turn into knowledge improvements. These measures help separate weak source material from weak retrieval and weak generation.
Knowledge operations
RAG creates an ongoing knowledge operations problem. Someone must decide which sources are approved, remove duplicates, archive outdated material, resolve policy conflicts, and review questions the agent could not answer. Buyers should ask whether support operations, product operations, documentation, or IT will own that loop. Without a named owner, retrieval quality usually degrades as products, policies, and customer language change.
Ownership after launch
The owner of RAG quality should have authority to change source material, not just read analytics. If support teams find repeated retrieval misses but documentation owners cannot update articles quickly, the agent will keep failing in the same way. A useful operating loop connects failed questions, source fixes, re-indexing, regression tests, and reviewer signoff before the updated knowledge is trusted in production.
Agentic RAG
Agentic RAG extends traditional RAG by allowing the AI agent to take multiple retrieval steps, call tools, and refine its search based on intermediate results. Instead of a single retrieve-then-generate pass, the agent can decide to search again, try different queries, call APIs, or combine information from multiple sources through iterative reasoning. This matters for AI agent platforms because complex business questions often require multi-step investigation: a support agent might first retrieve the refund policy, then check the customer's order status via API, then retrieve product-specific warranty terms before answering.
- Iterative retrieval: the agent can issue multiple queries, refine based on what it finds, and decide when to stop searching.
- Tool augmentation: the agent combines document retrieval with database lookups, API calls, and calculations, not just static text.
- Self-correction: when initial retrieval returns poor results, the agent can rephrase, broaden, or pivot rather than hallucinating.
- Memory across turns: agentic RAG often maintains context from earlier turns in a conversation, allowing follow-up questions without re-retrieving everything.
- Plan-and-execute: some agentic RAG systems plan a retrieval strategy before executing, reducing wasted effort on irrelevant paths.
For buyers evaluating AI agent platforms, agentic RAG capabilities become important when the use case involves complex, multi-step investigations rather than simple FAQ-style answers. Ask vendors whether retrieval is single-pass or iterative, whether the agent can call tools mid-retrieval, and how the system handles cases where the first search returns nothing useful. A single-pass RAG system will struggle with questions like "why was my account charged twice this month?" where the answer requires retrieving billing policy, checking transaction history via API, and comparing dates.
Hybrid search
Hybrid search combines multiple retrieval methods - typically keyword (BM25), vector similarity, and sometimes semantic reranking - to improve retrieval quality. Pure keyword search misses synonyms and conceptual matches. Pure vector search can miss exact matches or be thrown off by embedding noise. Hybrid search reduces both failure modes by ranking results from multiple methods and merging them intelligently.
- Keyword search (BM25): matches exact terms and phrases. Strong for product names, SKUs, error codes, and specific identifiers. Weak for conceptual questions or paraphrased intent.
- Vector search (semantic): matches meaning by comparing embedding vectors. Strong for paraphrased questions, conceptual matches, and cross-language retrieval. Weak for exact identifiers and sometimes confused by similar-sounding concepts.
- Reranking: a second-stage model scores initial results more carefully, often using a cross-encoder that jointly evaluates query and document. Reranking improves precision at the cost of latency.
- Fusion: results from keyword and vector search are combined using reciprocal rank fusion or learned scoring, then optionally reranked.
For AI agent buyers, hybrid search is often worth asking about. A vendor that relies only on vector search may miss exact matches that a customer would expect to find. A vendor that relies only on keyword search may fail on natural-language queries that use different wording than the documentation. Ask demo questions that mix conceptual and exact-term needs: "What's the difference between the Pro and Enterprise pricing tiers?" (requires finding pricing pages and comparing) or "How do I fix error 503?" (requires matching the error code while understanding the context).
Multimodal retrieval
Multimodal retrieval extends RAG beyond text to include images, tables, videos, audio, and structured data. Business knowledge is often multimodal: product manuals contain diagrams and tables, help centers include screenshots, support tickets have attached photos, and policy documents embed charts. A text-only RAG system will miss information locked in non-text formats, leading to incomplete or incorrect answers.
- Images: retrieving diagrams, screenshots, product photos, and error screenshots. Requires vision-capable embeddings or OCR pipelines.
- Tables: extracting structured data from PDFs, spreadsheets, and HTML tables. Tables often contain pricing, specifications, and comparison data that text chunking destroys.
- Video and audio: indexing timestamps, transcripts, and visual frames from training videos, webinars, and recorded support calls.
- Structured data: querying databases, APIs, and knowledge graphs alongside unstructured documents. Enables answers that combine narrative explanation with live data.
For buyers, multimodal support matters when the knowledge base includes non-text assets. Ask whether the platform can index and retrieve from PDFs with embedded images, whether tables are preserved as structured data rather than broken into incoherent text chunks, and whether image-based queries (like "show me the wiring diagram for model X") are supported. A platform that only indexes text will return incomplete answers for products with visual documentation, assembly instructions with diagrams, or support tickets with error screenshots.
Chunking strategies
Chunking is how documents are split into retrievable units before indexing. Chunk size and overlap affect retrieval quality dramatically. Small chunks preserve specific details but lose context. Large chunks preserve context but dilute relevance and consume context-window budget. Overlap helps ensure relevant passages aren't cut at boundaries. Semantic chunking attempts to split at concept boundaries rather than arbitrary character or sentence limits.
- Chunk size: typically 200-1000 tokens. Smaller chunks improve precision for specific questions but may miss surrounding context. Larger chunks provide context but may retrieve irrelevant material.
- Overlap: 10-20% overlap between chunks helps ensure relevant passages span chunk boundaries. No overlap risks cutting key information in half.
- Semantic chunking: uses sentence embeddings or structure (headings, paragraphs, sections) to split at meaning boundaries rather than fixed sizes. Preserves coherent ideas but requires more processing.
- Parent-child chunking: retrieves small chunks for relevance but loads larger parent chunks for context. Balances precision and context.
- Table and code chunking: requires special handling. Tables should often be chunked as units or rows with headers preserved. Code chunks need function context.
Chunking quality often explains why the same documents produce different answers across platforms. For buyers, ask how the platform handles chunking, whether there are controls for chunk size and overlap, whether tables and code are handled specially, and whether chunking can be tuned per document type. A vendor that treats all documents the same will struggle with mixed content types: a 50-page PDF policy manual needs different chunking than a set of short FAQ entries.
Embedding model considerations
Embedding models convert text into vector representations for semantic search. The choice of embedding model affects retrieval quality, language coverage, domain specificity, and cost. Newer models often outperform older ones, but switching embedding models requires re-indexing the entire corpus. Buyers should understand what embedding model a platform uses, how often it's updated, and what happens when models are upgraded.
- Model quality: embedding models differ in their ability to capture semantic similarity, handle different languages, and represent domain-specific terminology. A model trained on general web text may struggle with medical, legal, or technical documentation.
- Model size and speed: larger models often produce better embeddings but cost more to run. For high-volume retrieval, the tradeoff between quality and latency matters.
- Domain adaptation: some platforms allow fine-tuning embeddings on domain data. This can improve retrieval for specialized vocabulary but adds complexity and maintenance cost.
- Multilingual support: embedding models vary in language coverage. A model trained primarily on English may perform poorly on other languages, affecting global deployments.
- Model upgrades and re-indexing: when embedding models are updated or replaced, all documents must be re-embedded. Ask whether upgrades are automatic, whether they cause downtime, and whether retrieval quality regressions are monitored.
For buyers evaluating platforms, embedding model choice is often invisible but impactful. Ask what embedding model is used, whether it supports the languages needed, whether domain adaptation is available, and what happens when the model is updated. A platform that locks you into an outdated embedding model will see retrieval quality degrade relative to competitors who upgrade.
Reranking models
Reranking is a second-stage retrieval step that re-scores initial results using a more powerful (usually cross-encoder) model. After initial retrieval via keyword or vector search returns perhaps 50-100 candidate passages, a reranker jointly evaluates each query-document pair to produce a more accurate relevance score. Reranking improves precision at the cost of added latency.
- Cross-encoders: the reranking model sees both query and document together, allowing it to capture interactions that bi-encoder embedding models miss. This produces better relevance scores but is slower.
- Reranking APIs: some platforms use external reranking APIs (Cohere, Jina, Voyage, etc.) while others host reranking models internally. Externally hosted reranking may add latency and data transfer concerns.
- Top-k selection: reranking is typically applied to the top 20-100 initial results. After reranking, only the top few are passed to the generation model.
- Quality-latency tradeoff: reranking improves answer relevance but adds 50-500ms latency per query. For real-time support, this tradeoff must be evaluated.
- Cost: reranking is more computationally expensive than initial retrieval. For high-volume systems, the cost of reranking every query adds up.
For buyers, reranking is a capability to ask about specifically. A platform that only does initial retrieval may return less relevant results for ambiguous queries. A platform with reranking may produce better answers but with higher latency and cost. Ask whether reranking is included, whether it's applied by default, whether there are controls for when to rerank, and how the vendor measures the quality improvement. A demo that looks great on carefully chosen questions may not show the value of reranking on messy real-world queries.
Sources to verify
Use these references to understand the term and pressure-test vendor claims. Product-specific details still need to be verified against current vendor materials.
FAQ
Common questions
Is RAG the same as training an AI model?
No. Training changes model behavior. RAG retrieves external information at response time, so the quality depends heavily on the connected sources, retrieval logic, and freshness of the indexed content.
Does RAG prevent hallucinations?
No. RAG can reduce unsupported answers when retrieval and source quality are strong, but it does not guarantee accuracy. Buyers still need fallback behavior, source review, testing, and human oversight for risky workflows.
Is RAG the same as semantic search?
No. Semantic search helps retrieve relevant information, often by matching meaning rather than exact keywords. RAG uses retrieval as one step in a larger pattern: retrieve relevant context, pass it to a generative model, and produce an answer. A system can have semantic search without generation, and it can generate text without doing reliable retrieval.
Is uploading documents to a chatbot the same as RAG?
Not by itself. Uploaded documents can be used in a RAG system if the chatbot retrieves relevant passages from those documents at answer time and uses them as context for generation. But a file upload button does not prove how retrieval works, whether the right passages are selected, whether sources are fresh, or whether the answer stays grounded in the retrieved material. For buyers, the test is to inspect the retrieval step, source visibility, and failure behavior.
How is RAG different from fine-tuning?
Fine-tuning changes model behavior by training on additional examples or data. RAG retrieves external information at response time and uses it as context for the answer. RAG is often better suited for changing business knowledge because sources can be updated without retraining, but quality still depends on retrieval, permissions, and source hygiene.
What should buyers test in a RAG demo?
Use questions with one clear source, questions requiring multiple sources, outdated-policy traps, permission-sensitive content, synonyms customers actually use, and questions where the correct answer should be unknown. Ask to see retrieved sources, not just the final response, so you can tell whether the answer was grounded or merely fluent.
What causes RAG systems to give wrong answers?
Wrong answers can come from stale sources, conflicting documents, poor chunking, weak retrieval, missing metadata, permission mistakes, context-window limits, or a model that ignores the retrieved material. Debugging RAG requires separating source problems, retrieval problems, grounding problems, and generation problems instead of treating every failure as a prompt issue.
Who should own RAG quality after launch?
RAG quality needs an operational owner with authority to improve source material. Support operations, product operations, documentation, or knowledge management may own content quality, while technical teams own indexing, permissions, retrieval configuration, and monitoring. Without a closed loop between failed answers and source updates, retrieval quality usually degrades over time.
Does RAG work with private or permissioned data?
It can, but buyers should verify permission handling carefully. The system needs to respect who is allowed to retrieve each source, whether restricted content can appear in answers, how access changes are synced, and how retrieval is logged. Permission mistakes can turn a useful knowledge system into a data exposure risk.
What is the difference between RAG and agentic RAG?
Basic RAG retrieves once and generates. Agentic RAG allows the agent to take multiple retrieval steps, call tools, and refine searches based on intermediate results. Agentic RAG is better for complex, multi-step questions that require combining information from multiple sources or APIs. For simple FAQ-style questions, basic RAG is often sufficient.
Why does chunking matter for RAG quality?
Chunking determines how documents are split into retrievable units. Poor chunking can cut relevant information in half, lose context around key passages, or retrieve irrelevant fragments. Smaller chunks improve precision but lose surrounding context. Larger chunks preserve context but dilute relevance. Semantic chunking attempts to split at meaning boundaries rather than arbitrary limits, which often produces better results for complex documents.
Should I ask vendors about hybrid search?
Yes. Hybrid search combines keyword and vector retrieval, which catches both exact matches (like error codes and product names) and conceptual matches (paraphrased questions). A system that only does vector search may miss exact identifiers. A system that only does keyword search may fail on natural-language questions. Ask whether the platform supports both, whether reranking is included, and how results are merged.
Do I need multimodal RAG if my documents are mostly text?
It depends on your content. If your help center includes screenshots, product diagrams, pricing tables, or PDFs with embedded images, a text-only RAG system will miss information locked in those formats. For products with visual documentation, assembly instructions, or error screenshots, multimodal retrieval may be essential. Ask whether the platform can index and retrieve from images, tables, and structured data, not just text.
What should I know about embedding models?
Embedding models convert text into vector representations for semantic search. The choice of model affects retrieval quality, language coverage, and domain specificity. Ask what embedding model the platform uses, whether it supports the languages you need, whether domain adaptation is available, and what happens when the model is updated. Switching embedding models requires re-indexing all documents.
Is reranking worth the extra latency?
Reranking improves relevance by re-scoring initial results with a more powerful model. For ambiguous queries or large document sets, reranking often produces better answers. The tradeoff is added latency (typically 50-500ms per query) and cost. For real-time support where latency matters, test whether reranking improves answer quality enough to justify the delay. For batch or asynchronous use cases, reranking is usually worth it.